
Trouble In the House of Google
Let’s look at where stackoverflow.com traffic came from for the year of 2010.
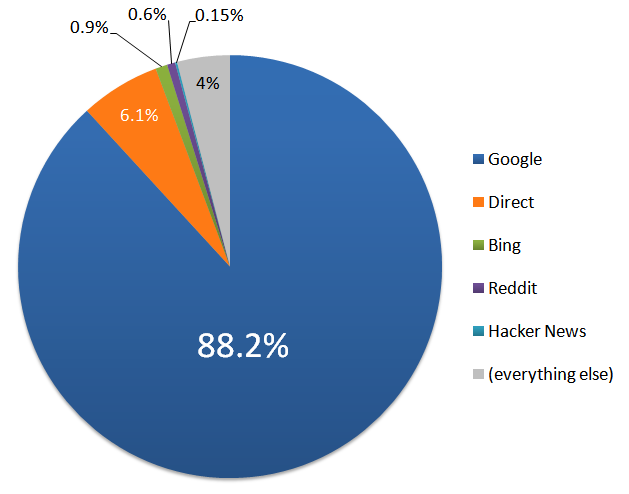
When 88.2% of all traffic for your website comes from a single source, criticizing that single source feels… risky. And perhaps a bit churlish, like looking a gift horse in the mouth, or saying something derogatory in public about your Valued Business Partnertm.
Still, looking at the statistics, it’s hard to avoid the obvious conclusion. I’ve been told many times that Google isn’t a monopoly, but they apparently play one on the internet. You are perfectly free to switch to whichever non-viable alternative web search engine you want at any time. Just breathe in that sweet freedom, folks.
Sarcasm aside, I greatly admire Google. My goal is not to be acquired, because I’m in this thing for the long haul – but if I had to pick a company to be acquired by, it would probably be Google. I feel their emphasis on the information graph over the social graph aligns more closely with our mission than almost any other potential suitor I can think of. Anyway, we’ve been perfectly happy with Google as our de-facto traffic sugar daddy since the beginning. But last year, something strange happened: the content syndicators began to regularly outrank us in Google for our own content.
Syndicating our content is not a problem. In fact, it’s encouraged. It would be deeply unfair of us to assert ownership over the content so generously contributed to our sites and create an underclass of digital sharecroppers. Anything posted to Stack Overflow, or any Stack Exchange Network site for that matter, is licensed back to the community in perpetuity under Creative Commons cc-by-sa. The community owns their contributions. We want the whole world to teach each other and learn from the questions and answers posted on our sites. Remix, reuse, share – and teach your peers! That’s our mission. That’s why I get up in the morning.

However, implicit in this strategy was the assumption that we, as the canonical source for the original questions and answers, would always rank first. Consider Wikipedia – when was the last time you clicked through to a page that was nothing more than a legally copied, properly attributed Wikipedia entry encrusted in advertisements? Never, right? But it is in theory a completely valid, albeit dumb, business model. That’s why Joel Spolsky and I were confident in sharing content back to the community with almost no reservations – because Google mercilessly penalizes sites that attempt to game the system by unfairly profiting on copied content. Remixing and reusing is fine, but mass-producing cheap copies encrusted with ads… isn’t.
I think of this as common sense, but it’s also spelled out explicitly in Google’s webmaster content guidelines.
However, some webmasters attempt to improve their page’s ranking and attract visitors by creating pages with many words but little or no authentic content. Google will take action against domains that try to rank more highly by just showing scraped or other auto-generated pages that don’t add any value to users. Examples include:
Scraped content. Some webmasters make use of content taken from other, more reputable sites on the assumption that increasing the volume of web pages with random, irrelevant content is a good long-term strategy. Purely scraped content, even from high-quality sources, may not provide any added value to your users without additional useful services or content provided by your site. It’s worthwhile to take the time to create original content that sets your site apart. This will keep your visitors coming back and will provide useful search results.
In 2010, our mailboxes suddenly started overflowing with complaints from users – complaints that they were doing perfectly reasonable Google searches, and ending up on scraper sites that mirrored Stack Overflow content with added advertisements. Even worse, in some cases, the original Stack Overflow question was nowhere to be found in the search results! That’s particularly odd because our attribution terms require linking directly back to us, the canonical source for the question, without nofollow. Google, in indexing the scraped page, cannot avoid seeing that the scraped page links back to the canonical source. This culminated in, of all things, a special browser plug-in that redirects to Stack Overflow from the ripoff sites. How totally depressing. Joel and I thought this was impossible. And I felt like I had personally failed all of you.
The idea that there could be something wrong with Google was inconceivable to me. Google is gravity on the web, an omnipresent constant; blaming Google would be like blaming gravity for my own clumsiness. It wasn’t even an option. I started with the golden rule: it’s always my fault. We did a ton of due diligence on webmasters.stackexchange.com to ensure we weren’t doing anything overtly stupid, and uber-mensch Matt Cutts went out of his way to investigate the hand-vetted search examples contributed in response to my tweet asking for search terms where the scrapers dominated. Issues were found on both sides, and changes were made. Success!
Despite the semi-positive resolution, I was disturbed. If these dime-store scrapers were doing so well and generating so much traffic on the back of our content – how was the rest of the web faring? My enduring faith in the gravitational constant of Google had been shaken. Shaken to the very core.
Throughout my investigation I had nagging doubts that we were seeing serious cracks in the algorithmic search foundations of the house that Google built. But I was afraid to write an article about it for fear I’d be claimed an incompetent kook. I wasn’t comfortable sharing that opinion widely, because we might be doing something obviously wrong. Which we tend to do frequently and often. Gravity can’t be wrong. We’re just clumsy… right?
I can’t help noticing that we’re not the only site to have serious problems with Google search results in the last few months. In fact, the drum beat of deteriorating Google search quality has been practically deafening of late:
- Why We Desperately Need a New (and Better) Google
- Dishwashers, and How Google Eats Its Own Tail
- Content Farms: Why Media, Blogs & Google Should Be Worried
- On the increasing uselessness of Google
- Google, Google, Why Hast Thou Forsaken the Manolo?
Anecdotally, my personal search results have also been noticeably worse lately. As part of Christmas shopping for my wife, I searched for “iPhone 4 case” in Google. I had to give up completely on the first two pages of search results as utterly useless, and searched Amazon instead.
People whose opinions I respect have all been echoing the same sentiment – Google, the once essential tool, is somehow losing its edge. The spammers, scrapers, and SEO’ed-to-the-hilt content farms are winning.
Like any sane person, I’m rooting for Google in this battle, and I’d love nothing more than for Google to tweak a few algorithmic knobs and make this entire blog entry moot. Still, this is the first time since 2000 that I can recall Google search quality ever declining, and it has inspired some rather heretical thoughts in me – are we seeing the first signs that algorithmic search has failed as a strategy? Is the next generation of search destined to be less algorithmic and more social?
It’s a scary thing to even entertain, but maybe gravity really is broken.



