To ECC or Not To ECC
On one of my visits to the Computer History Museum – and by the way this is an absolute must-visit place if you are ever in the San Francisco bay area – I saw an early Google server rack circa 1999 in the exhibits.

Not too fancy, right? Maybe even… a little janky? This is building a computer the Google way:
Instead of buying whatever pre-built rack-mount servers Dell, Compaq, and IBM were selling at the time, Google opted to hand-build their server infrastructure themselves. The sagging motherboards and hard drives are literally propped in place on handmade plywood platforms. The power switches are crudely mounted in front, the network cables draped along each side. The poorly routed power connectors snake their way back to generic PC power supplies in the rear.
Some people might look at these early Google servers and see an amateurish fire hazard. Not me. I see a prescient understanding of how inexpensive commodity hardware would shape today’s internet. I felt right at home when I saw this server; it’s exactly what I would have done in the same circumstances. This rack is a perfect example of the commodity x86 market D.I.Y. ethic at work: if you want it done right, and done inexpensively, you build it yourself.
This rack is now immortalized in the National Museum of American History. Urs Hölzle posted lots more juicy behind the scenes details, including the exact specifications:
- Supermicro P6SMB motherboard
- 256MB PC100 memory
- Pentium II 400 CPU
- IBM Deskstar 22GB hard drives (×2)
- Intel 10/100 network card
When I left Stack Exchange (sorry, Stack Overflow) one of the things that excited me most was embarking on a new project using 100% open source tools. That project is, of course, Discourse.
Inspired by Google and their use of cheap, commodity x86 hardware to scale on top of the open source Linux OS, I also built our own servers. When I get stressed out, when I feel the world weighing heavy on my shoulders and I don’t know where to turn… I build servers. It’s therapeutic.
Don’t judge me, man.
But more seriously, with the release of Intel’s latest Skylake architecture, it’s finally time to upgrade our 2013 era Discourse servers to the latest and greatest, something reflective of 2016 – which means building even more servers.
Discourse runs on a Ruby stack and one thing we learned early on is that Ruby demands exceptional single threaded performance, aka, a CPU running as fast as possible. Throwing umptazillion CPU cores at Ruby doesn’t buy you a whole lot other than being able to handle more requests at the same time. Which is nice, but doesn’t get you speed per se. Someone made a helpful technical video to illustrate exactly how this all works:
This is by no means exclusive to Ruby; other languages like JavaScript and Python also share this trait. And Discourse itself is a JavaScript application delivered through the browser, which exercises the mobile / laptop / desktop client CPU. Mobile devices reaching near-parity with desktop performance in single threaded performance is something we’re betting on in a big way with Discourse.
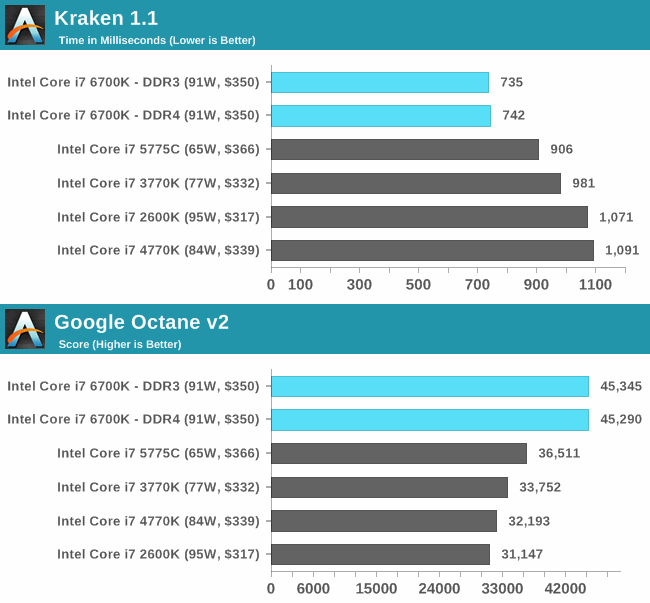
So, good news! Although PC performance has been incremental at best in the last 5 years, between Haswell and Skylake, Intel managed to deliver a respectable per-thread performance bump. Since we are upgrading our servers from Ivy Bridge (very similar to the i7-3770k), the generation before Haswell, I’d expect a solid 33% performance improvement at minimum.
Even worse, the more cores they pack on a single chip, the slower they all go. From Intel’s current Xeon E5 lineup:
- E5-1680 → 8 cores, 3.2 Ghz
- E5-1650 → 6 cores, 3.5 Ghz
- E5-1630 → 4 cores, 3.7 Ghz
Sad, isn’t it? Which brings me to the following build for our core web tiers, which optimizes for “lots of inexpensive, fast boxes.”
| 2013 | 2016 |
| Xeon E3-1280 V2 Ivy Bridge 3.6 Ghz / 4.0 Ghz quad-core ($640) SuperMicro X9SCM-F-O mobo ($190) 32 GB DDR3-1600 ECC ($292) SC111LT-330CB 1U chassis ($200) Samsung 830 512GB SSD ×2 ($1080) 1U Heatsink ($25) | i7-6700k Skylake 4.0 Ghz / 4.2 Ghz quad-core ($370) SuperMicro X11SSZ-QF-O mobo ($230) 64 GB DDR4-2133 ($520) CSE-111LT-330CB 1U chassis ($215) Samsung 850 Pro 1TB SSD ×2 ($886) 1U Heatsink ($20) |
| $2,427 | $2,241 |
| 31w idle, 87w BurnP6 load | 14w idle, 81w BurnP6 load |
So, about 10% cheaper than what we spent in 2013, with 2× the memory, 2× the storage (probably 50-100% faster too), and at least ~33% faster CPU. With lower power draw, to boot! Pretty good. Pretty, pretty, pretty, pretty good.
(Note that the memory bump is only possible thanks to Intel finally relaxing their iron fist of maximum allowed RAM at the low end; that’s new to the Skylake generation.)
One thing is conspicuously missing in our 2016 build: Xeons, and ECC Ram. In my defense, this isn’t intentional – we wanted the fastest per-thread performance and no Intel Xeon, either currently available or announced, goes to 4.0 GHz with Skylake. Paying half the price for a CPU with better per-thread performance than any Xeon, well, I’m not going to kid you, that’s kind of a nice perk too.
Error-correcting code memory (ECC memory) is a type of computer data storage that can detect and correct the most common kinds of internal data corruption. ECC memory is used in most computers where data corruption cannot be tolerated under any circumstances, such as for scientific or financial computing.
Typically, ECC memory maintains a memory system immune to single-bit errors: the data that is read from each word is always the same as the data that had been written to it, even if one or more bits actually stored have been flipped to the wrong state. Most non-ECC memory cannot detect errors although some non-ECC memory with parity support allows detection but not correction.
It’s received wisdom in the sysadmin community that you always build servers with ECC RAM because, well, you build servers to be reliable, right? Why would anyone intentionally build a server that isn’t reliable? Are you crazy, man? Well, looking at that cobbled together Google 1999 server rack, which also utterly lacked any form of ECC RAM, I’m inclined to think that reliability measured by “lots of redundant boxes” is more worthwhile and easier to achieve than the platonic ideal of making every individual server bulletproof.
Being the type of guy who likes to question stuff… I began to question. Why is it that ECC is so essential anyway? If ECC was so important, so critical to the reliable function of computers, why isn’t it built in to every desktop, laptop, and smartphone in the world by now? Why is it optional? This smells awfully... enterprisey to me.
Now, before everyone stops reading and I get permanently branded as “that crazy guy who hates ECC,” I think ECC RAM is fine:
- The cost difference between ECC and not-ECC is minimal these days.
- The performance difference between ECC and not-ECC is minimal these days.
- Even if ECC only protects you from rare 1% hardware error cases that you may never hit until you literally build hundreds or thousands of servers, it’s cheap insurance.
I am not anti-insurance, nor am I anti-ECC. But I do seriously question whether ECC is as operationally critical as we have been led to believe, and I think the data shows modern, non-ECC RAM is already extremely reliable.
First, let’s look at the Puget Systems reliability stats. These guys build lots of commodity x86 gamer PCs, burn them in, and ship them. They helpfully track statistics on how many parts fail either from burn-in or later in customer use. Go ahead and read through the stats.
For the last two years, CPU reliability has dramatically improved. What is interesting is that this lines up with the launch of the Intel Haswell CPUs which was when the CPU voltage regulation was moved from the motherboard to the CPU itself. At the time we theorized that this should raise CPU failure rates (since there are more components on the CPU to break) but the data shows that it has actually increased reliability instead.
Even though DDR4 is very new, reliability so far has been excellent. Where DDR3 desktop RAM had an overall failure rate in 2014 of ~0.6%, DDR4 desktop RAM had absolutely no failures.
SSD reliability has dramatically improved recently. This year Samsung and Intel SSDs only had a 0.2% overall failure rate compared to 0.8% in 2013.
Modern commodity computer parts from reputable vendors are amazingly reliable. And their trends show from 2012 onward essential PC parts have gotten more reliable, not less. (I can also vouch for the improvement in SSD reliability as we have had zero server SSD failures in 3 years across our 12 servers with 24+ drives, whereas in 2011 I was writing about the Hot/Crazy SSD Scale.) And doesn’t this make sense from a financial standpoint? How does it benefit you as a company to ship unreliable parts? That’s money right out of your pocket and the reseller’s pocket, plus time spent dealing with returns.
We had a, uh, “spirited” discussion about this internally on our private Discourse instance.

This is not a new debate by any means, but I was frustrated by the lack of data out there. In particular, I’m really questioning the difference between “soft” and “hard” memory errors:
But what is the nature of those errors? Are they soft errors – as is commonly believed – where a stray Alpha particle flips a bit? Or are they hard errors, where a bit gets stuck?
I absolutely believe that hard errors are reasonably common. RAM DIMMS can have bugs, or the chips on the DIMM can fail, or there’s a design flaw in circuitry on the DIMM that only manifests in certain corner cases or under extreme loads. I’ve seen it plenty. But a soft error where a bit of memory randomly flips?
There are two types of soft errors, chip-level soft error and system-level soft error. Chip-level soft errors occur when the radioactive atoms in the chip’s material decay and release alpha particles into the chip. Because an alpha particle contains a positive charge and kinetic energy, the particle can hit a memory cell and cause the cell to change state to a different value. The atomic reaction is so tiny that it does not damage the actual structure of the chip.
Outside of airplanes and spacecraft, I have a difficult time believing that soft errors happen with any frequency, otherwise most of the computing devices on the planet would be crashing left and right. I deeply distrust the anecdotal voodoo behind “but one of your computer’s memory bits could flip, you’d never know, and corrupted data would be written!” It’d be one thing if we observed this regularly, but I’ve been unhealthily obsessed with computers since birth and I have never found random memory corruption to be a real, actual problem on any computers I have either owned or had access to.
But who gives a damn what I think. What does the data say?
A 2007 study found that the observed soft error rate in live servers was two orders of magnitude lower than previously predicted:
Our preliminary result suggests that the memory soft error rate in two real production systems (a rack-mounted server environment and a desktop PC environment) is much lower than what the previous studies concluded. Particularly in the server environment, with high probability, the soft error rate is at least two orders of magnitude lower than those reported previously. We discuss several potential causes for this result.
A 2009 study on Google’s server farm notes that soft errors were difficult to find:
We provide strong evidence that memory errors are dominated by hard errors, rather than soft errors, which previous work suspects to be the dominant error mode.
Yet another large-scale study from 2012 discovered that RAM errors were dominated by permanent failure modes typical of hard errors:
Our study has several main findings. First, we find that approximately 70% of DRAM faults are recurring (e.g., permanent) faults, while only 30% are transient faults. Second, we find that large multi-bit faults, such as faults that affects an entire row, column, or bank, constitute over 40% of all DRAM faults. Third, we find that almost 5% of DRAM failures affect board-level circuitry such as data (DQ) or strobe (DQS) wires. Finally, we find that chipkill functionality reduced the system failure rate from DRAM faults by 36x.
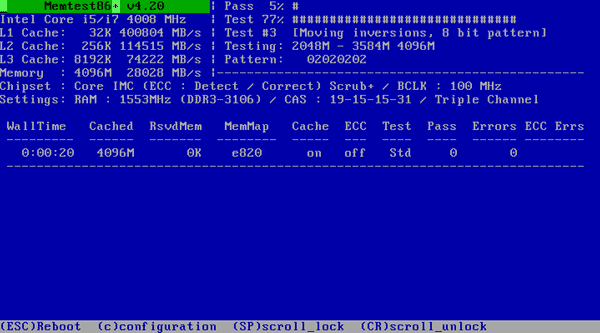
In the end, we decided the non-ECC RAM risk was acceptable for every tier of service except our databases. Which is kind of a bummer since higher end Skylake Xeons got pushed back to the big Purley platform upgrade in 2017. Regardless, we burn in every server we build with a complete run of memtestx86 and overnight prime95/mprime, and you should too. There’s one whirring away through endless memory tests right behind me as I write this.
I find it very, very suspicious that ECC – if it is so critical to preventing these random, memory corrupting bit flips – has not already been built into every type of RAM that we ship in the ubiquitous computing devices all around the world as a cost of doing business. But I am by no means opposed to paying a small insurance premium for server farms, either. You’ll have to look at the data and decide for yourself. Mostly I wanted to collect all this information in one place so people who are also evaluating the cost/benefit of ECC RAM for themselves can read the studies and decide what they want to do.
Please feel free to leave comments if you have other studies to cite, or significant measured data to share.