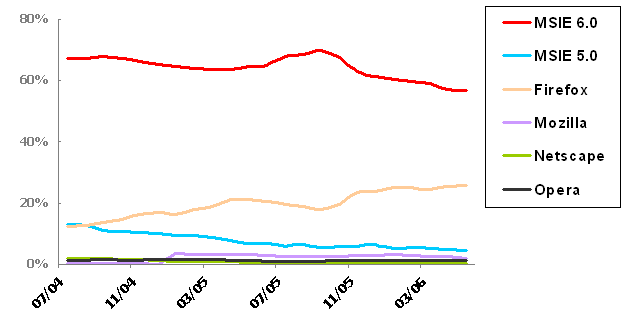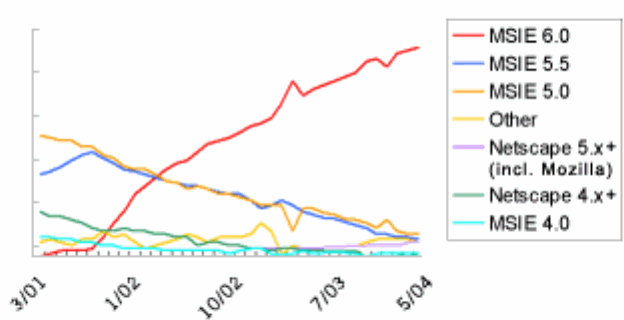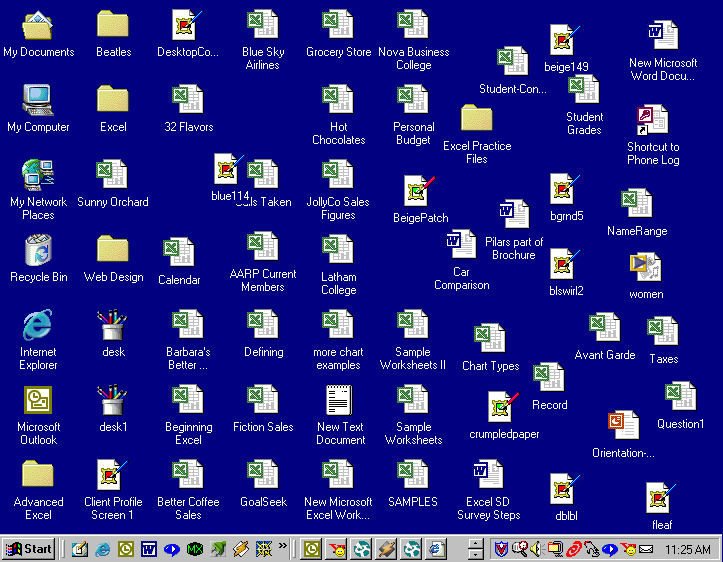
desktop organization
Desktopitis
This guy* who gave a presentation with Patrick Cauldwell yesterday revealed his desktop during the presentation. Here’s what it looked like: After the presentation, I ribbed him about his desktop. You have a few square millimeters of desktop left uncovered, I said. Clearly you have your work cut out