Obscenity Filters: Bad Idea, or Incredibly Intercoursing Bad Idea?
I’m not a huge fan of The Daily WTF for reasons I’ve previously outlined. There is, however, the occasional gem – such as this one posted by ezrec:
Browsing through a web archive of some old computer club conversations, I ran across this sentence:
“Apple made the clbuttic mistake of forcing out their visionary - I mean, look at what NeXT has been up to!”
Hmm. “clbuttic.”
Google “clbuttic” - thousands of hits!
There’s a someone who call his car ‘clbuttic.’
There are “Clbuttic Steam Engine” message boards.
Webster’s dictionary - no help.
Hmm. What can this be?
As programmers, this isn’t much of a mystery to us; it seems every day a brand new software developer is born and immediately begins repeating all the same mistakes we made years ago. I can’t resist linking to Language Log again on this topic, where a commenter disputes whether or not this is an actual real world problem:
The “clbuttics” story may be a little exaggerated if not actually a web-legend. Sure, Google returns 4,000 hits – but by the time one reaches page 2 (in search of a page that isn’t reporting on the silliness, or reporting on the reports, etc.) we’re down to 200 hits.
Almost all of those 200 seem to have a “clbuttic mistake” by Apple at their core. Google’s redundancy-compacting routines are only invoked when requested, it seems, and even then, the variety of information in 200 hits may be small.
In short, it’s an echo chamber. 200 or 4,000 or however many hits today aren’t as impressive as the same number last year, etc. All the more so as web sites of all kinds put randomly chosen (even Googled!) words out there just to game Google.
While I agree this particular manifestation of the mistake is probably over-reported (because, haha, butts are funny) and fairly rare on the open web, I still get this shiner on page one of my search results:
Is the song Dueling Banjos considered blue grbutt?
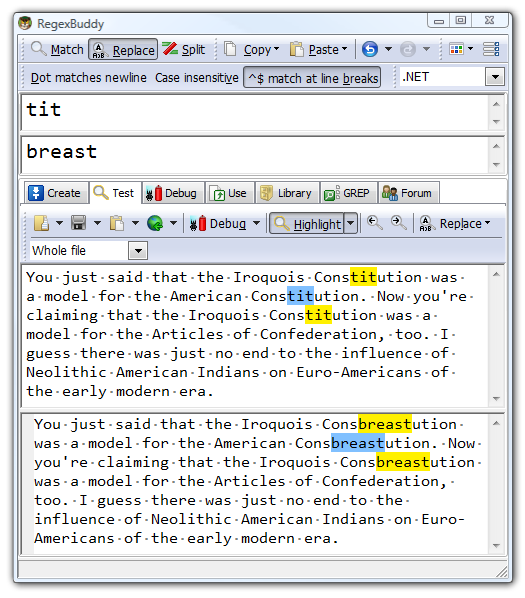
Poor Bluegrass World. I’m pretty sure that site is legitimate, though I have no idea how they’d post an article in that state. Obligatory link to dueling banjos scene from Deliverance. I’m inclined to believe this is, in fact, still a problem. There are many, many examples besides “clbuttic” out there. Perhaps you’ve heard of the United States Consbreastution?
Of course, what we have here is failed obscenity filters implemented by (extremely) newbie developers with regular expressions. I could explain, but as they say, a picture is worth a thousand words, particularly when it’s a picture of my very bestest friend, RegexBuddy:
Oh, great, an inexperienced developer had a problem, and thought they would use regular expressions. Now they have two problems. Well, technically through Google they now have many thousands of problems, but who’s counting.
I’m not sure regular expressions are to blame here. The replacement is so mind-bendingly naïve that it might as well have been a simple Replace operation. We, being extra-smart-gets-things-done developers, would write a superior regular expression using the b word boundary qualifier around the replacement, and use some capturing parens to handle both the singular and plural cases.
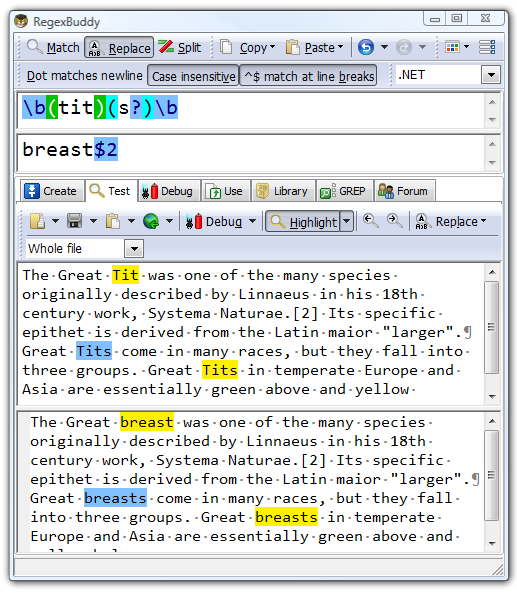
How about those Great Tits, eh?
Proving, yet again, that bad ideas are just plain bad ideas, regardless of language or implementation choices. Obscenity filters are like blacklists; using one is tantamount to admitting failure before you’ve even started.
But it still happens all the time. One of the most famous incidents was when the Yahoo! email developers created the accidental non-word Medireview. They weren’t trying to filter obscenities, but JavaScript webmail exploits.
In 2001 Yahoo! silently introduced an email filter which changed some strings in HTML emails considered to be dangerous. While it was intended to stop spreading JavaScript viruses, no attempts were made to limit these string replacements to script sections and attributes, out of fear this would leave some loophole open. Additionally, word boundaries were not respected in the replacement.
The list of replacements:
Javascript → java-script Jscript → j-script Vbscript → vb-script Livescript → live-script Eval → review Mocha → espresso Expression → statement
Some side-effects of this implementation:
| medieval | → | medireview |
| evaluation | → | reviewuation |
| expressionist | → | statementist |
medireview.com is currently occupied by domain squatters. Perhaps that’s a fitting end for this “company,” though I perversely almost want the company to exist, as wholly formed from our imaginations, sort of like Jamcracker.
I can’t help wondering just how freaked out the brass at Yahoo must have been about then-new JavaScript browser exploits to actually deploy such a brain-damaged “solution.” To be fair, it was seven years ago, but still – did it not occur to anyone that such broad replacement criteria might have some serious side-effects? Or that replacing one thing with another, when it comes to human beings and written language, is an activity that is fraught with peril even in the best possible circumstances?
Obscenity filtering is an enduring, maybe even timeless problem. I’m doubtful it will ever be possible to solve this particular problem through code alone. But it seems some companies and developers can’t stop tilting at that windmill. Which means you might want to think twice before you move to Scunthorpe.