Programming Is Hard, Let’s Go Shopping!
A few months ago, Dare Obasanjo noticed a brief exchange my friend Jon Galloway and I had on Twitter. Unfortunately, Twitter makes it unusually difficult to follow conversations, but Dare outlines the gist of it in Developers, Using Libraries is not a Sign of Weakness:
The problem Jeff was trying to solve is how to allow a subset of HTML tags while stripping out all other HTML so as to prevent cross site scripting (XSS) attacks. The problem with Jeffs approach which was pointed out in the comments by many people including Simon Willison is that using regexes to filter HTML input in this way assumes that you will get fairly well-formed HTML. The problem with that approach which many developers have found out the hard way is that you also have to worry about malformed HTML due to the liberal HTML parsing policies of many modern Web browsers. Thus to use this approach you have to pretty much reverse engineer every HTML parsing quirk of common browsers if you don’t want to end up storing HTML which looks safe but actually contains an exploit. Thus to utilize this approach Jeff really should have been looking at using a full fledged HTML parser such as SgmlReader or Beautiful Soup instead of regular expressions.
The sad thing is that Jeff Atwood isn’t the first nor will he be the last programmer to think to himself “It’s just HTML sanitization, how hard can it be?” There are many lists of Top HTML Validation Bloopers that show how tricky it is to get the right solution to this seemingly trivial problem. Additionally, it is sad to note that despite his recent experience, Jeff Atwood still argues that he’d rather make his own mistakes than blindly inherit the mistakes of others as justification for continuing to reinvent the wheel in the future. That is unfortunate given that is a bad attitude for a professional software developer to have.
My response?
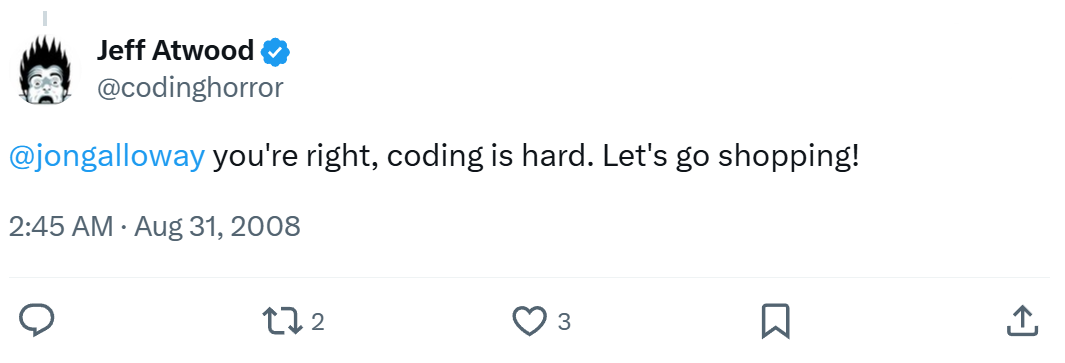
Bad attitude? I think that’s a matter of perspective.
(The phase “programming is hard, let’s go shopping!” is a snowclone. As usual, Language Log has us covered. Ironically, we later had a brief run-in with Consultant Barbie “herself” on Stack Overflow – who you may know from reddit. There’s no trace of her left on SO, but as griefing goes, it was fairly benign and even arguably on-topic.)
In the development of Stack Overflow, I determined early on that we’d be using Markdown for entering questions and answers in the system. Unfortunately, Markdown allows users to intermix HTML into the markup. It’s part of the spec and everything. I sort of wish it wasn’t, actually – one of the great attractions of pseudo-markup languages like BBCode is that they have nothing in common with HTML and thus sanitizing the input becomes trivial. Users have two choices:
- Enter approved pseudo-markup.
- Trick question. There is no other choice!
With BBCode, if the user enters HTML you blow it away with extreme prejudice – it’s encoded, without exceptions. Easy. No thinking and barely any code required.
Since we use Markdown, we don’t have that luxury. Like it or not, we are now in the nasty, brutish business of distinguishing “good” HTML markup from “evil” HTML markup. That’s hard. Really hard. Dare and Jon are right to question the competency and maybe even the sanity of any developer who willingly decided to bite off that particular problem.
But here’s the thing: deeply understanding HTML sanitization is a critical part of my business. Users entering markdown isn’t just some little tick box in a feature matrix for me, it is quite literally the entire foundation that our website is built on.
Here’s a pop quiz from way back in 2001. See how you do.
- Code Reuse is:
- Good
- Bad
- Reinventing the Wheel is:
- Good
- Bad
- The Not-Invented-Here Syndrome is:
- Good
- Bad
I’m sure most developers are practically climbing over each other in their eagerness to answer at this point. Of course code reuse is good. Of course reinventing the wheel is bad. Of course the not-invented-here syndrome is bad.
Except when it isn’t.
If it’s a core business function – do it yourself, no matter what.
Pick your core business competencies and goals, and do those in house. If you’re a software company, writing excellent code is how you’re going to succeed. Go ahead and outsource the company cafeteria and the CD-ROM duplication. If you’re a pharmaceutical company, write software for drug research, but don’t write your own accounting package. If you’re a web accounting service, write your own accounting package, but don’t try to create your own magazine ads. If you have customers, never outsource customer service.
Being a “professional” developer, if there really is such a thing – I still have my doubts – doesn’t mean choosing third-party libraries for every possible programming task you encounter. Nor does it mean blindly writing everything yourself out of a misguided sense of duty or the perception that’s what gonzo, hardcore programming types do. Rather, experienced developers learn what their core business functions are and write whatever software they deem necessary to perform those functions extraordinarily well.
Do I regret spending a solid week building a set of HTML sanitization functions for Stack Overflow? Not even a little. There are plenty of sanitization solutions outside the .NET ecosystem, but precious few for C# or VB.NET. I’ve contributed the core code back to the community, so future .NET adventurers can use our code as a guidepost (or warning sign, depending on your perspective) on their own journey. They can learn from the simple, proven routine we wrote and continue to use on Stack Overflow every day.
(Sadly this code outlasted the refactormycode website, so I’ve reprinted the final version here; consider this MIT licensed.)
private static Regex _tags = new Regex("<[^>]*(>|$)",
RegexOptions.Singleline | RegexOptions.ExplicitCapture | RegexOptions.Compiled);
private static Regex _whitelist = new Regex(@"
^</?(b(lockquote)?|code|d(d|t|l|el)|em|h(1|2|3)|i|kbd|li|ol|p(re)?|s(ub|up|trong|trike)?|ul)>$|
^<(b|h)r\s?/?>$",
RegexOptions.Singleline | RegexOptions.ExplicitCapture | RegexOptions.Compiled | RegexOptions.IgnorePatternWhitespace);
private static Regex _whitelist_a = new Regex(@"
^<a\s
href=""(\#\d+|(https?|ftp)://[-a-z0-9+&@#/%?=~_|!:,.;\(\)]+)""
(\stitle=""[^""<>]+"")?\s?>$|
^</a>$",
RegexOptions.Singleline | RegexOptions.ExplicitCapture | RegexOptions.Compiled | RegexOptions.IgnorePatternWhitespace);
private static Regex _whitelist_img = new Regex(@"
^<img\s
src=""https?://[-a-z0-9+&@#/%?=~_|!:,.;\(\)]+""
(\swidth=""\d{1,3}"")?
(\sheight=""\d{1,3}"")?
(\salt=""[^""<>]*"")?
(\stitle=""[^""<>]*"")?
\s?/?>$",
RegexOptions.Singleline | RegexOptions.ExplicitCapture | RegexOptions.Compiled | RegexOptions.IgnorePatternWhitespace);
/// <summary>
/// sanitize any potentially dangerous tags from the provided raw HTML input using
/// a whitelist based approach, leaving the "safe" HTML tags
/// CODESNIPPET:4100A61A-1711-4366-B0B0-144D1179A937
/// </summary>
public static string Sanitize(string html)
{
if (String.IsNullOrEmpty(html)) return html;
string tagname;
Match tag;
// match every HTML tag in the input
MatchCollection tags = _tags.Matches(html);
for (int i = tags.Count - 1; i > -1; i--)
{
tag = tags[i];
tagname = tag.Value.ToLowerInvariant();
if(!(_whitelist.IsMatch(tagname) || _whitelist_a.IsMatch(tagname) || _whitelist_img.IsMatch(tagname)))
{
html = html.Remove(tag.Index, tag.Length);
System.Diagnostics.Debug.WriteLine("tag sanitized: " + tagname);
}
}
return html;
}
Honestly, I’m not that great of a developer. I’m not so much talented as competent and loud. Start writing and talking and you can be loud, too. But I’ll tell you this: in choosing to fight that HTML sanitizer battle, I’ve earned the scars of experience. I don’t have to take anybody’s word for it – I don’t have to trust “libraries.” I can look at the code, examine the input and output, and predict exactly what kinds of problems might arise. I have a deep and profound understanding of the risks, pitfalls, and tradeoffs of HTML sanitization... and cross-site scripting vulnerabilities.

As Richard Feynman so famously wrote on his last blackboard, what I cannot create, I do not understand.
This is exactly the kind of programming experience I need to keep watch over Stack Overflow, and I wouldn’t trade it for anything. You may not be building a website that depends on users entering markup, so you might make a different decision than I did. But surely there’s something, some core business competency, so important that you feel compelled to build it yourself, even if it means making your own mistakes.
Programming is hard. But that doesn’t mean you should always go shopping for third party libraries instead of writing code. If it’s a core business function, write that code yourself, no matter what. If other programmers don’t understand why it’s so critically important that you sit down and write that bit of code – well, that’s their problem.
They’re probably too busy shopping to understand.