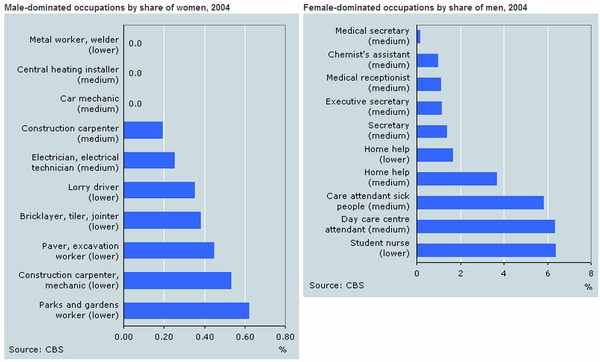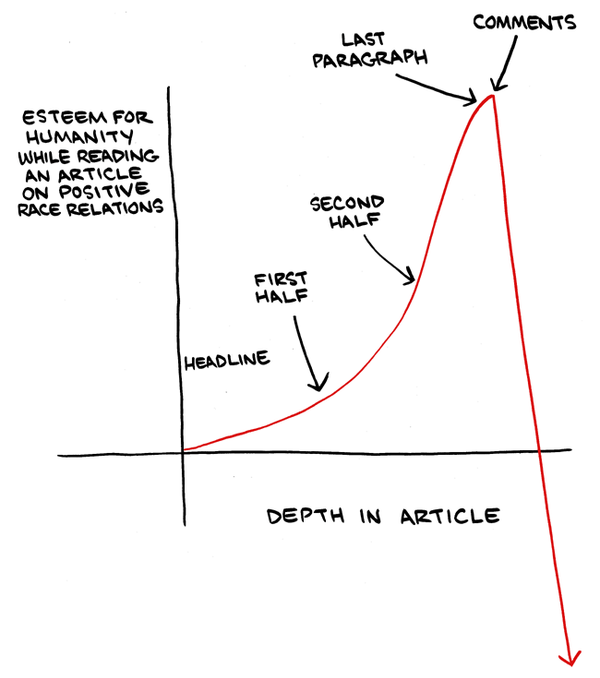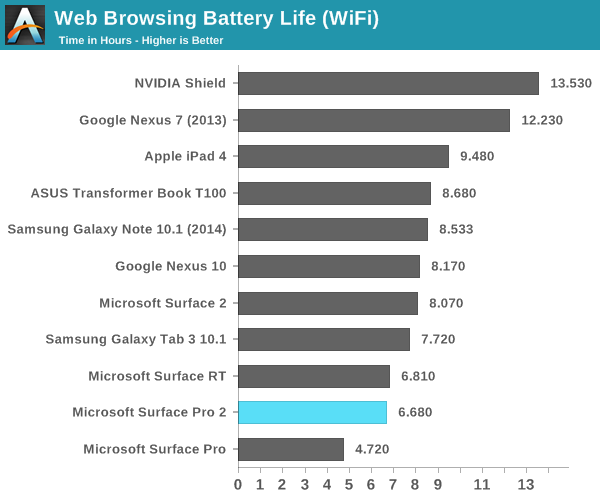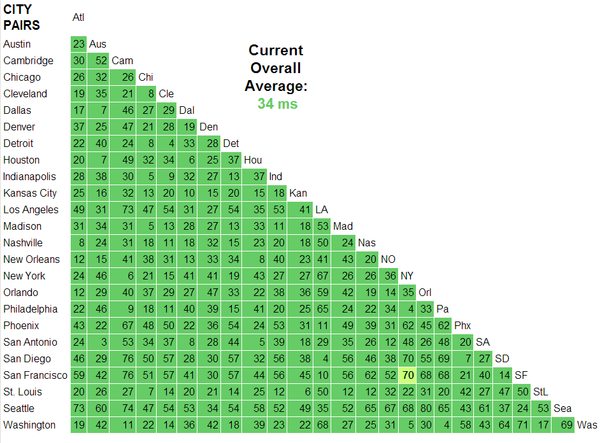
programming languages
The Infinite Space Between Words
Computer performance is a bit of a shell game. You’re always waiting for one of four things: * Disk * CPU * Memory * Network But which one? How long will you wait? And what will you do while you’re waiting? Did you see the movie “Her”? If not, you should. It’