The Day The Trackbacks Died
You might read a post on this blog and decide I’m full of crap. That’s fine. I often am full of crap. I encourage you to leave a comment explaining why you feel this way. And, while you’re at it, feel free to point out any errors or inaccuracies in anything I’ve written. This kind of simple, immediate, highly visible public dialog is why I believe so strongly in comments as an essential part of blogging.
But sometimes a mere comment isn’t enough. Maybe you have your own blog. Depending on the depth of your feelings on the matter, you might want to write an entire post on your blog explaining, in great detail, specifically why I’m full of crap. Then you’d publish your post for the world to see. But how do you know that I, the target of your vitriol, have read your post? How do you know that I can even find your post? You could email me directly, but that feels a little too intimate. Or, you could leave a comment linking to your response, but that feels like additional work.
The answer lies in trackbacks. Trackbacks are a way of relating conversations across websites. After you publish your post, you send a trackback to my post. This is usually handled automatically by the blogging software. The trackback links our two posts together. I get notified of any trackbacks to my posts, so I can follow the trackback to read your response. Furthermore, trackbacks are public, just like comments. So any future readers can also follow our conversation thread by directly navigating from my blog to yours with a single click. Tom Coates created a little diagram which illustrates this process:
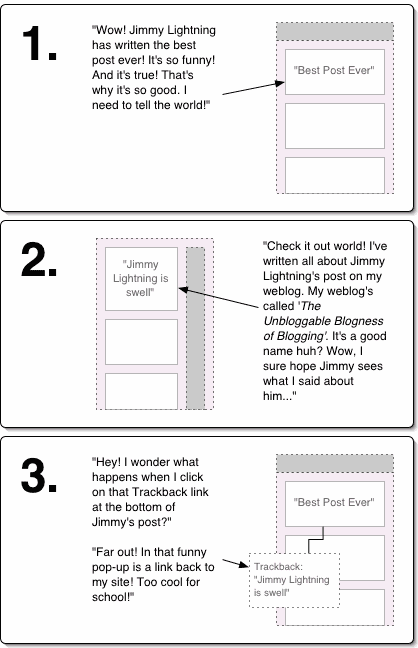
They’re a great idea. Unfortunately, trackbacks are so horribly and fundamentally broken that they’re effectively useless.
The original trackback specification was published by Six Apart in summer 2002. It’s very basic. The trackback URL is published in the metadata embedded in every blog post:
<rdf:Description
rdf:about=“https://blog.codinghorror.com/the-programmers-bill-of-rights/”
trackback:ping=“http://www.codinghorror.com/mtype/mt-tb.cgi/666”
dc:title=“The Programmer’s Bill of Rights”
dc:identifier=“https://blog.codinghorror.com/the-programmers-bill-of-rights/”
dc:creator=“Jeff Atwood”
dc:date=“2006-08-24T23:59:59-08:00” />
You simply HTTP POST a bit of data to the trackback URL of the post you’re commenting on, like so:
POST http://www.codinghorror.com/mtype/mt-tb.cgi/666 Content-Type: application/x-www-form-urlencoded; charset=utf-8 title=He’s+full+of+crap&url=http://www.bar.com/&blog_name=Foo
See? Simple. And it works great. In one swell foop, you’ve created a coherent conversation that flows across two totally different websites!
Well, it was great. Until the spammers realized two things:
- how high the pagerank is for popular blogs (7+)
- how trivially easy it is to abuse the trackback mechanism because trackbacks have no authentication mechanism whatsoever.
CAPTCHA has completely solved my comment spam problem. But distinguishing between humans and machines is useless on trackbacks, which are all machine entered by definition. I’ve fought the good fight against the rising tide of trackbacks with various blacklists over the last three years, but as this blog grows more and more popular, I’m clearly losing the war. Malicious spammers can batch register dirt-cheap domain names and write scripts to mass-POST these URLs all over the blogosphere far, far faster than I can ever hope to blacklist them. Every day starts with a depressing routine of adding 4-8 new spam URLs to my blacklist.
Yes, there are distributed blacklists like Akismet. Yes, you can put all your trackbacks into a moderation queue and spend 5 minutes every day deleting them all manually. Yes, you could retrieve the linking page and make sure it contains the promised link to your post. But these are only slightly larger band-aids over a massive, sucking chest wound. These aren’t sustainable solutions. We have a much deeper problem. Trackbacks, as we currently know them, are dead, kaput, expired.
It’s an absolute travesty, and I completely blame Six Apart’s initial trackback specification. How could they forget the rich history of email spam we’ve had to deal with for the last ten years? Trackbacks, as a result of Six Apart’s incredibly naive initial design, are now a total loss. That’s what happens when you design social software without considering the impact of malicious users from the very beginning.
Now, hopefully you’ll understand why I’ve disabled all trackbacks for this blog as of today.
But I still believe in the concept of trackbacks. I want to read your response to my posts, whether it’s on your site, or mine as a comment. So rather than relying on direct peer-to-peer links, I’m exploring the use of external indexing services. I experimented with using Google searches to find all the pages that have linked to the URL of a post, but I wasn’t happy with the results. For now, I’ve replaced the automatic trackback with a bit of JavaScript from Technorati which automatically lists any blogs that linked to a particular post. It’s not quite as egalitarian as I’d like, because you have to join Technorati to participate. And it’s another unwanted external dependency which I’ll have to deal with. But it’s the best I can do for now.
And please, if you’re designing social software, try to avoid repeating the many mistakes of our forefathers. Again. Design from day one with the assumption that a few of your users will be evil. If you don’t, like Six Apart, your naïvite will make the entire community suffer sooner or later.