programming practices
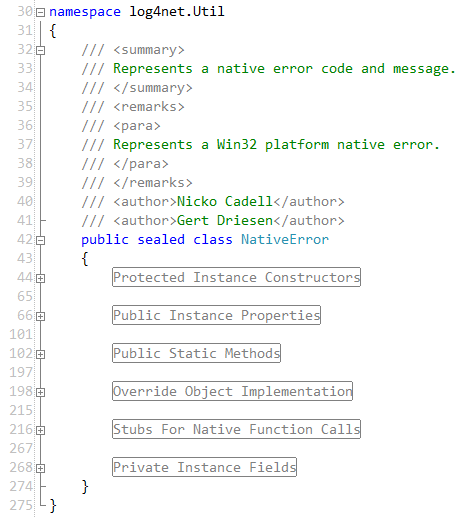
The Problem With Code Folding
When you join a team, it’s important to bend your preferences a little to accommodate the generally accepted coding practices of that team. Not everyone has to agree on every miniscule detail of the code, of course, but it’s a good idea to discuss it with your team