If you use virtual machines at all, you should have the single most important virtual machine performance tip committed to heart by now: always run your virtual machines from a separate physical hard drive:
[the] biggest performance win is to put the virtual hard disks on separate disk spindles from the operating system. The biggest performance hit in virtual machines is disk I/O. Making the VM fight with your OS and swap disk makes this issue much, much worse. Additionally, today's USB 2.0 and firewire external hard drives run on a fast interface bus, have large buffers and spin at 7,200 rpm, as opposed to 4,200 rpm for most laptop hard drives.
I've talked about virtualization performance penalties before, but this bears repeating. I originally read this tip at Scott's blog, and I've heard it echoed in emails directly from the Virtual PC Guy himself.
It's true that most laptop drives are at 5,400 rpm these days, and a scant few even run at 7,200 rpm. But the tip is still as valid as ever. The primary performance bottleneck in virtual machines, by a very wide margin, is the hard drive. Although it's possible to squeeze a complete install of Windows XP into a 641 megabyte VM hard drive image file, most VM hard drive image files rapidly grow to multiple gigabytes. It's not unusual to see VMs end up 5 or 10 gigabytes in size. It shouldn't be too surprising that the disk subsystem has a disproportionately large impact on overall virtual machine performance.
That's one reason why all the desktop machines I build now have two hard drives:
- A faster, smaller drive for the operating system and essential applications. You can't beat the 10,000 rpm Western Digital Raptor series for this role.
- A larger data drive for virtual machines and everything else.
This way, whenever I boot up a VM, it's running from a different physical spindle than the operating system, and thus running at optimal speeds. It's also a good way to segregate your operating system and data in case you need to do a complete wipe of your operating system. And it's certainly a much safer and more practical two drive approach than RAID-0 on the desktop.
Unfortunately, we can't drop a second drive into our laptops. But there's another solution that works almost as well: external SATA and USB2 enclosures. These enclosures offer the best of both worlds: high-speed USB 2.0 interfaces for laptops, and full-speed eSATA connections for desktops.


The Icy Dock, pictured above, is one of the best of these new enclosures. It's a bit spendy, but it's remarkably well made from mostly aluminum, with a clever locking tray mechanism. It also includes all the extras you need to connect it to your PC, including a USB 2.0 cable, an eSATA bracket, and an eSATA cable. Just add the desktop SATA drive of your choice.
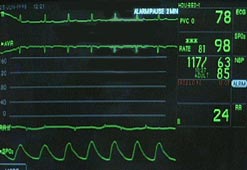
I've talked about the difference between USB 2.0 and full-blown SATA performance before. Here's a direct comparison between a modern 250 gigabyte 7,200 rpm SATA drive in the Icy Dock (connected via USB), and my laptop's internal 100 gigabyte 5,400 rpm hard drive:
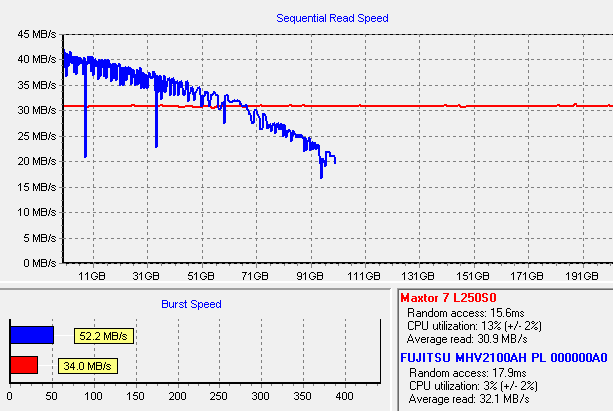
The USB 2.0 interface is nothing to sneeze at. With a fast 7,200 rpm desktop drive mounted, it does a little better than the internal laptop drive overall, once you factor in random access times and the constant speed across the entire drive. But it's obviously limited by the interface. That's why the option to connect a drive via its native SATA interface is so desirable in an external enclosure. Some recent motherboards even include eSATA connectors on their back panel, such as the Asus P5B that I recently built. I presume it's only a matter of time before some enterprising laptop manufacturer releases a laptop with an eSATA connector.
It's not a slam-dunk performance victory over the internal laptop drive in absolute terms. But the real-world performance improvement gained from running a VM on an external USB 2.0 drive is quite noticeable. Recommended.
Discussion