HTML Validation: Does It Matter?
The web is, to put it charitably, a rather forgiving place. You can feed web browsers almost any sort of HTML markup or JavaScript code and they’ll gamely try to make sense of what you’ve provided, and render it the best they can. In comparison, most programming languages are almost cruelly unforgiving. If there’s a single character out of place, your program probably won’t compile, much less run. This makes the HTML + JavaScript environment a rather unique – and often frustrating – software development platform.
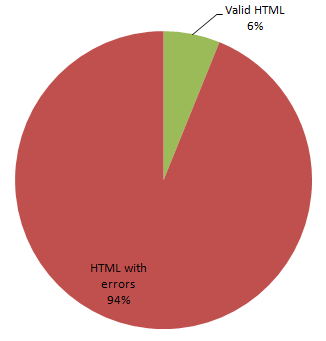
But it doesn’t have to be this way. There are provisions and mechanisms for validating your HTML markup through the official W3C Validator. Playing with the validator underscores how deep that forgiveness by default policy has permeated the greater web. Dennis Forbes recently ran a number of websites through the validator, including this one, with predictably bad results:
FAIL - http://www.reddit.com - 36 errors as XHTML 1.0 Transitional. EDIT: Rechecked Reddit, and now it’s a PASS
FAIL - http://www.slashdot.org - 167 errors as HTML 4.01 Strict
FAIL - http://www.digg.com - 32 errors as XHTML 1.0 Transitional
FAIL - http://www.cnn.com - 40 errors as HTML 4.01 Transitional (inferred as no doctype was specified)
FAIL - http://www.microsoft.com - 193 errors as XHTML 1.0 Transitional
FAIL - http://www.google.com - 58 errors as HTML 4.01 Transitional
FAIL - http://www.flickr.com - 34 errors as HTML 4.01 Transitional
FAIL - http://ca.yahoo.com - 276 errors as HTML 4.01 Strict
FAIL - http://www.sourceforge.net - 65 errors as XHTML 1.0 Transitional
FAIL - http://www.joelonsoftware.com - 33 errors as XHTML 1.0 Strict
FAIL - http://www.stackoverflow.com - 58 errors as HTML 4.01 Strict
FAIL - http://www.dzone.com - 165 errors as XHTML 1.0 Transitional
FAIL - http://www.codinghorror.com/blog/ - 51 errors as HTML 4.01 Transitional
PASS - http://www.w3c.org - no errors as XHTML 1.0 Strict
PASS - http://www.linux.com - no errors as XHTML 1.0 Strict
PASS - http://www.wordpress.com - no errors as XHTML 1.0 Transitional
In short, we live in malformed world. So much so that you begin to question whether validation matters at all. If you see this logo on a site, what does it mean to you? How will it affect your experience on that website? As a developer? As a user?

We just went through the exercise of validating Stack Overflow’s HTML. I almost immediately ruled out the idea of validating as XHTML, because I vehemently agree with James Bennett:
The short and sweet reason is simply this: XHTML offers no compelling advantage – to me – over HTML, but even if it did it would also offer increased complexity and uncertainty that make it unappealing to me.
The whole HTML validation exercise is questionable, but validating as XHTML is flat-out masochism. Only recommended for those that enjoy pain. Or programmers. I can’t always tell the difference.
Anyway, we validated as the much saner HTML 4.01 strict, and even then I’m not sure it was worth the time we spent. So many of these validation rules feel arbitrary and meaningless. And, what’s worse, some of them are actively harmful. For example, this is not allowed in HTML strict:
<a href=“http://www.example.com/” target=“_blank”>foo</a>
That’s right, target, a perfectly harmless attribute for links that you want to open in a different browser tab/window, is somehow verboten in HTML 4.01 strict. There’s an officially supported workaround, but it’s only implemented by Opera, so in effect... there is no workaround.
In order to comply with the HTML 4.01 strict validator, you need to remove that target attribute and replace it with JavaScript that does the same thing. So, immediately I began to wonder: Is anybody validating our JavaScript? What about our CSS? Is anyone validating the DOM manipulations that JavaScript performs on our HTML? Who validates the validator? Why can’t I stop thinking about zebras?
Does it really matter if we render stuff this way...
<td width=“80”> <br/>
<td style=“width:80px”> <br>
I mean, who makes up these rules? And for what reason?
I couldn’t help feeling that validating as HTML 4.01 strict, at least in our case, was a giant exercise in to-may-to versus to-mah-to, punctuated by aggravating changes that we were forced to make for no practical benefit. (Also, if you have a ton of user-generated content like we do, you can pretty much throw any fantasies of 100% perfect validation right out the window.)
That said, validation does have its charms. There were a few things that the validation process exposed in our HTML markup that were clearly wrong – an orphaned tag here, and a few inconsistencies in the way we applied tags there. Mark Pilgrim makes the case for validation:
I am not claiming that your page, once validated, will automatically render flawlessly in every browser; it may not. I am also not claiming that there aren’t talented designers who can create old-style “Tag Soup” pages that do work flawlessly in every browser; there certainly are. But the validator is an automated tool that can highlight small but important errors that are difficult to track down by hand. If you create valid markup most of the time, you can take advantage of this automation to catch your occasional mistakes. But if your markup is nowhere near valid, you’ll be flying blind when something goes wrong. The validator will spit out dozens or even hundreds of errors on your page, and finding the one that is actually causing your problem will be like finding a needle in a haystack.
There is some truth to this. Learning the rules of the validator, even if you don’t agree with them, teaches you what the official definition of “valid” is. It grounds your markup in reality. It’s sort of like passing your source code through an ultra-strict lint validation program, or setting your compiler to the strictest possible warning level. Knowing the rules and boundaries helps you define what you’re doing, and gives you legitimate ammunition for agreeing or disagreeing. You can make an informed choice, instead of a random “I just do this and it works” one.
After jumping through the HTML validation hoops ourselves, here’s my advice:
- Validate your HTML. Know what it means to have valid HTML markup. Understand the tooling. More information is always better than less information. Why fly blind?
- Nobody cares if your HTML is valid. Except you. If you want to. Don’t think for a second that producing perfectly valid HTML is more important than running your website, delivering features that delight your users, or getting the job done.
But the question remains: does HTML Validation really matter? Yes. No. Maybe. It depends. I’ll tell you the same thing my father told me: take my advice and do as you please.