gaming
DEFCON: Shall We Play a Game?
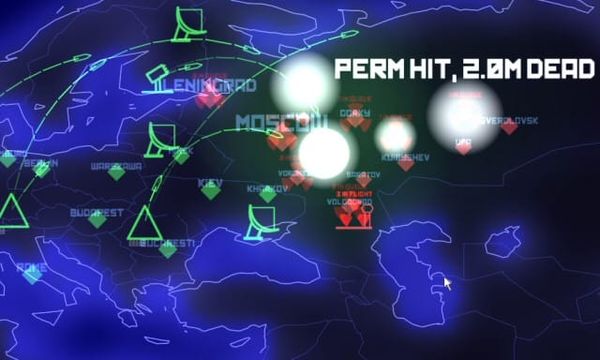
Earlier this year I wrote about how much I loved Introversion Software’s indie PC game Darwinia. Introversion just released their newest game, DEFCON. DEFCON channels WarGames and Balance of Power... ... but Defcon begins where Balance of Power ended, rewarding failure: It’s positively strangelovian. The developers nail the ambient