The Problem With URLs
URLs are simple things. Or so you’d think. Let’s say you wanted to detect an URL in a block of text and convert it into a bona fide hyperlink. No problem, right?
Visit my website at http://www.example.com, it’s awesome!
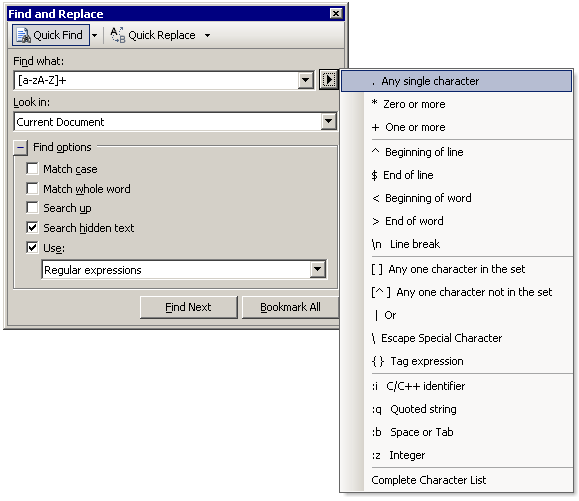
To locate the URL in the above text, a simple regular expression should suffice – we’ll look for a string at a word boundary beginning with http:// , followed by one or more non-space characters:
bhttp://[^s]+
Piece of cake. This seems to work. There’s plenty of forum and discussion software out there which auto-links using exactly this approach. Although it mostly works, it’s far from perfect. What if the text block looked like this?
My website (http://www.example.com) is awesome.
This URL will be incorrectly encoded with the final paren. This, by the way, is an extremely common way average everyday users include URLs in their text.
What’s truly aggravating is that parens in URLs are perfectly legal. They’re part of the spec and everything:
only alphanumerics, the special characters “$-_.+!*’(),” and reserved characters used for their reserved purposes may be used unencoded within a URL.
Certain sites, most notably Wikipedia and MSDN, love to generate URLs with parens. The sites are lousy with the damn things:
http://en.wikipedia.org/wiki/PC_Tools_(Central_Point_Software) http://msdn.microsoft.com/en-us/library/aa752574(VS.85).aspx
URLs with actual parens in them means we can’t take the easy way out and ignore the final paren. You could force users to escape the parens, but that’s sort of draconian, and it’s a little unreasonable to expect your users to know how to escape characters in the URL.
http://en.wikipedia.org/wiki/PC_Tools_%28Central_Point_Software%29 http://msdn.microsoft.com/en-us/library/aa752574%28VS.85%29.aspx
To detect URLs correctly in all most cases, you have to come up with something more sophisticated. Granted, this isn’t the toughest problem in computer science, but it’s one that many coders get wrong. Even coders with years of experience, like, say, Paul Graham.
If we’re more clever in constructing the regular expression, we can do a better job.
(?bhttp://[-A-Za-z0-9+&@#/%?=~_()|!:,.;]*[-A-Za-z0-9+&@#/%=~_()|]
- The primary improvement here is that we’re only accepting a whitelist of known good URL characters. Allowing arbitrary random characters in URLs is setting yourself up for XSS exploits, and I can tell you that from personal experience. Don’t do it!
- We only allow certain characters to “end” the URL. Ending a URL in common punctuation marks like period, exclamation point, semicolon, etc. means those characters will be considered end-of-hyperlink characters and not included in the URL.
- Parens, if present, are allowed in the URL – and we absorb the leading paren, if it is there, too.
I couldn’t come up with a way for the regex alone to distinguish between URLs that legitimately end in parens (ala Wikipedia), and URLs that the user has enclosed in parens. Thus, there has to be a handful of postfix code to detect and discard the user-enclosed parens from the matched URLs:
if (s.StartsWith("(") && s.EndsWith(")"))
{
return s.Substring(1, s.Length - 2);
}
That’s a whole lot of extra work, just because the URL spec allows parens. We can’t fix Wikipedia or MSDN and we certainly can’t change the URL spec. But we can ensure that our websites avoid becoming part of the problem. Avoid using parens (or any unusual characters, for that matter) in URLs you create. They’re annoying to use, and rarely handled correctly by auto-linking code.