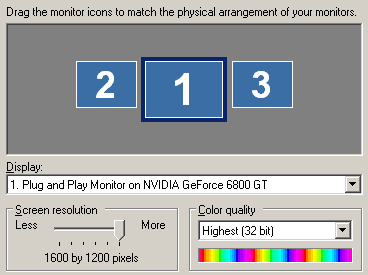
processor
Pentium-M Home Theater PC
I recently built a new, much lower wattage home theater PC using the Pentium-M processor. The P-M was, until very recently, a mobile-only part. And that’s why it’s ideal for HTPC duties – it offers very high levels of performance at an astonishingly modest power draw. For example, per