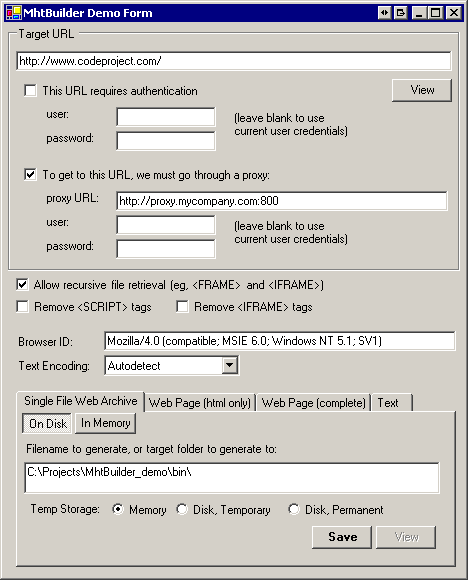
hashes
Checksums and Hashes
I learned to appreciate the value of the Cyclic Redundancy Check (CRC) algorithm in my 8-bit, 300 baud file transferring days. If the CRC of the local file matched the CRC stored in the file (or on the server), I had a valid download. I also learned a little bit