
Computers are Lousy Random Number Generators
The .NET framework provides two random number generators. The first is System.Random. But is it really random?
Pseudo-random numbers are chosen with equal probability from a finite set of numbers. The chosen numbers are not completely random because a definite mathematical algorithm is used to select them, but they are sufficiently random for practical purposes. The current implementation of the Random class is based on Donald E. Knuth’s subtractive random number generator algorithm, from The Art of Computer Programming: Seminumerical Algorithms, volume 2.
These cannot be random numbers because they’re produced by a computer algorithm; computers are physically incapable of randomness. But perhaps sufficiently random for practical purposes is enough.
The second method is System.Security.Cryptography.RandomNumberGenerator. It’s more than an algorithm. It also incorporates the following environmental factors in its calculations:
- The current process ID
- The current thread ID
- The tick count since boot time
- The current time
- Various high precision CPU performance counters
- An MD4 hash of the user’s environment (username, computer name, search path, etc.)
Good cryptography requires high quality random data. In fact, a perfect set of encrypted data is indistinguishable from random data.
I wondered what randomness looks like. So I wrote the following program, which compares the two random number methods available in the .NET framework. In blue, System.Random, and in red, System.Cryptography.RandomNumberGenerator.
const int maxlen = 3000;
Random r = new Random();
RandomNumberGenerator rng = RandomNumberGenerator.Create();
Byte[] b = new Byte[4];
using (StreamWriter sw = new StreamWriter(“random.csv”))
{
for (int i = 0; i < maxlen; i++)
{
sw.Write(r.Next());
sw.Write(“,”);
rng.GetBytes(b);
sw.WriteLine(Math.Abs(BitConverter.ToInt32(b, 0)));
}
}
3,000 random numbers
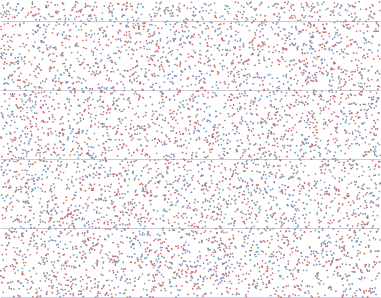
10,000 random numbers

30,000 random numbers

I have no idea how to test for true randomness. The math is far beyond me. But I don’t see any obvious patterns in the resulting data. It’s utterly random noise to my eye. Although both of these methods produce reasonable randomness, they’re ultimately still pseudo-random number generators. Computers are great number crunchers, but they’re lousy random number generators.
To have any hope of producing truly random data, you must reach outside the computer and sample the analog world. For example, WASTE samples user mouse movements to generate randomness:
But even something as seemingly random as user input can be predictable; not all environmental sources are suitably random:
True random numbers are typically generated by sampling and processing a source of entropy outside the computer. A source of entropy can be very simple, like the little variations in somebody’s mouse movements or in the amount of time between keystrokes. In practice, however, it can be tricky to use user input as a source of entropy. Keystrokes, for example, are often buffered by the computer’s operating system, meaning that several keystrokes are collected before they are sent to the program waiting for them. To the program, it will seem as though the keys were pressed almost simultaneously.
A better source of entropy is a radioactive source. The points in time at which a radioactive source decays are completely unpredictable, and can be sampled and fed into a computer, avoiding any buffering mechanisms in the operating system. In fact, this is what the HotBits people at Fourmilab in Switzerland are doing. Another source of entropy could be atmospheric noise from a radio, like that used here at random.org, or even just background noise from an office or laboratory. The lavarand people at Silicon Graphics have been clever enough to use lava lamps to generate random numbers, so their entropy source not only gives them entropy, it also looks good! The latest random number generator to come online is EntropyPool which gathers random bits from a variety of sources including HotBits and random.org, but also from web page hits received by the EntropyPool’s web server.
Carl Ellision has an excellent summary of many popular environmental sources of randomness and their strengths and weaknesses. But environmental sources have their limits, too – unlike pseudo-random algorithms, they have to be harvested over time. Not all environmental sources can provide enough random data for a server under heavy load, for example. And some encryption methods require more random data than others; one particularly secure algorithm requires one bit of random data for each bit of encrypted data.
Computers may be lousy random number generators, but we’ve still come a long way:
As recently as 100 years ago, people who needed random numbers for scientific work still tossed coins, rolled dice, dealt cards, picked numbers out of hats, or browsed census records for lists of digits. In 1927, statistician L.H.C. Tippett published a table of 41,600 random numbers obtained by taking the middle digits from area measurements of English churches. In 1955, the Rand Corporation published A Million Random Numbers With 100,000 Normal Deviates, a massive tome filled with tables of random numbers. To remove slight biases discovered in the course of testing, the million digits were further randomized by adding all pairs and retaining only the last digit. The Rand book became a standard reference, still used today in low-level applications such as picking precincts to poll.
The world is random. Computers aren’t. Randomness is really, really hard for computers. It’s important to understand the ramifications of this big divide between the analog and digital world, otherwise you’re likely to make the same rookie mistakes Netscape did.



