source control
Source Control: Anything But SourceSafe
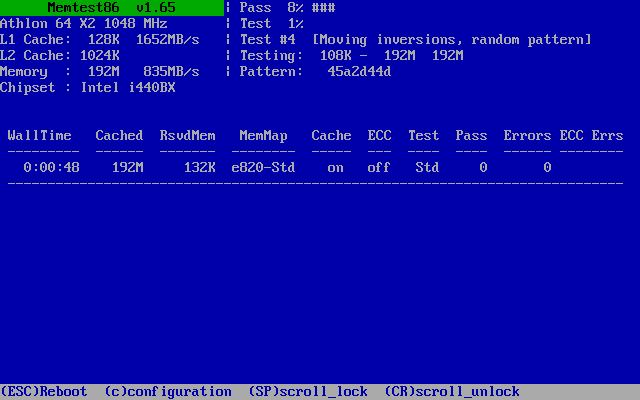
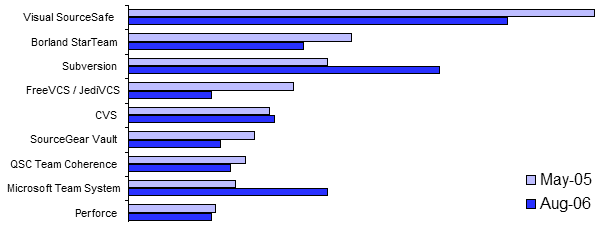
Everyone agrees that source control is fundamental to the practice of modern software development. However, there are dozens of source control options to choose from. VSoft, the makers of FinalBuilder, just published the results of their annual customer survey. One of the questions it asked was which version control systems