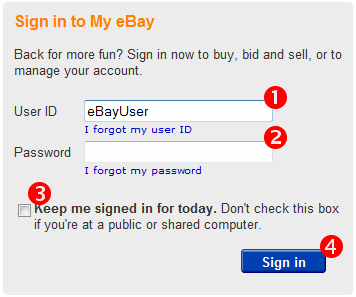
user experience
The Ultimate Unit Test Failure
We programmers are obsessive by nature. But I often get frustrated with the depth of our obsession over things like code coverage. Unit testing and code coverage are good things. But perfectly executed code coverage doesn’t mean users will use your program. Or that it’s even worth using