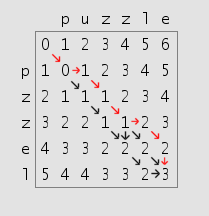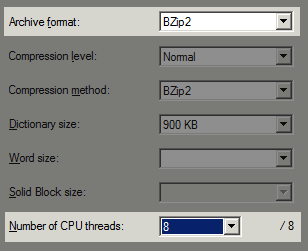
cpu cores
File Compression in the Multi-Core Era
I’ve been playing around a bit with file compression again, as we generate some very large backup files daily on Stack Overflow. We’re using the latest 64-bit version of 7zip (4.64) on our database server. I’m not a big fan of more than dual core on