If you ask a software developer what they spend their time doing, they'll tell you that they spend most of their time writing code.
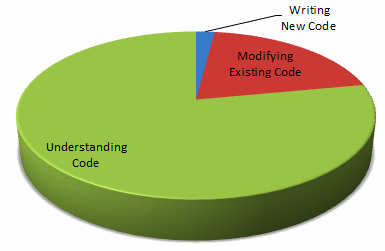
However, if you actually observe what software developers spend their time doing, you'll find that they spend most of their time trying to understand code:
Peter Hallam explains:
Why is 5x more time spent modifying code than writing new code? New code becomes old code almost instantly. Write some new code. Go for coffee. All of sudden you've got old code. Brand spanking new code reflects at most only the initial design however most design doesn't happen up front. Most development projects use the iterative development methodology. Design, code, test, repeat. Repeat a lot. Only the coding in the first iteration qualifies as all new code. After the first iteration coding quickly shifts to be more and more modifying rather than new coding. Also, almost all code changes made while bug fixing falls into the modifying code category. Look at [the Visual Studio development team]; our stabilization (aka bug fixing) milestones are as long as our new feature milestones. Modifying code consumes much more of a professional developer's time than writing new code.Why is 3x more time spend understanding code than modifying code? Before modifying code, you must first understand what it does. This is true of any refactoring of existing code - you must understand the behavior of the code so that you can guarantee that the refactoring didn't change anything unintended. When debugging, much more time is spent understanding the problem than actually fixing it. Once you've fixed the problem, you need to understand the new code to ensure that the fix was valid. Even when writing new code, you never start from scratch. You'll be calling existing code to do most of your work. Either user written code or a library supplied by Microsoft, or a third party for which no source is available. Before calling this existing code you must understand it in precise detail. When writing my first XML enabled app, I spent much more time figuring out the details of the XML class libraries than I did actually writing code. When adding new features you must understand the existing features so that you can reuse where appropriate. Understanding code is by far the activity at which professional developers spend most of their time.
I think the way most developers "understand" code is to rewrite it. Joel thinks rewriting code is always a bad idea. I'm not so sure it's that cut and dried. According to The Universe in a Nutshell, here's what was written on Richard Feynman's blackboard at the time of his death:
What I cannot create, I do not understand.
It's not that developers want to rewrite everything; it's that very few developers are smart enough to understand code without rewriting it. And as much as I believe in the virtue of reading code, I'm convinced that the only way to get better at writing code is to write code. Lots of it. Good, bad, and everything in between. Nobody wants developers to reinvent the wheel (again), but reading about how a wheel works is a poor substitute for the experience of driving around on a few wheels of your own creation.
Understanding someone else's code-- really comprehending how it all fits together-- takes a herculean amount of mental effort. And, even then, is source code truly the best way to understand an application? After reading Nate Comb's thought provoking blog entry, I wonder:
Would Martians wishing to understand the rules of the World of Warcraft (WoW) be better off trying to read its source code or watching video of millions of hours of screen capture?The challenge of Reginald's interview question is this: "If someone were to read the source code, do you think they could learn how to play [Monopoly]?"
In some ways this challenge hints of the reward of "downhill synthesis" over an "uphill analysis": who really knows what the rules of WoW are except by grace of the analysis of a million fan websites and trial and error. Do the developers really know?
I've worked on plenty of applications where, even with the crutch of source code I wrote myself, I had trouble explaining exactly how the application works. Imagine how difficult that explanation becomes with three, five, or twenty developers involved.
Does the source code really tell the story of the application? I'm not so sure. Maybe the best way to understand an application is, paradoxically, to ignore the source code altogether. If you want to know how the application really works, observe carefully how users use it. Then go write your own version.
Discussion