
asp.net
ASP.NET About Box (Page)
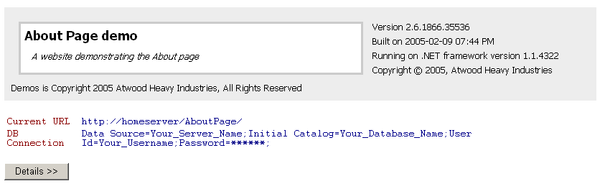
I had a request for an ASP.NET version of my windows forms About Box. This is a good idea that I’ve considered in the past, so I took the time to convert it today: Clicking details will provide a dump of all loaded assemblies in summary form, with