Obfuscating Code
Robert Cringeley, in a post early last year, raised some concerns about reverse engineering .NET code:
.NET is almost exclusively Just-In-Time compiled. JIT’ing means, “I was just about to interpret this, but I’ll compile it at the very last minute instead.” In effect, the .NET code remains in interpretation-intended form right up until the end. The point is that it carries around tons of info with it that makes reverse engineering easy just as with interpreted languages. The original Microsoft BASIC was an interpreted language and subject to this vulnerability, which is why it was so easy to copy on punched paper tape and why Bill Gates once referred to many of his earliest users as “thieves.” Many languages are interpreted including some of my favorites like Forth, PostScript, and Scheme. Java is interpreted and subject to this same vulnerability but the evolution of Java has led to it being used mainly for server applications where the source is a bit further out of reach. .NET, on the other hand, is Microsoft’s chosen successor to Visual BASIC, and effectively exposes source code at the very heart of Microsoft consumer and enterprise applications.
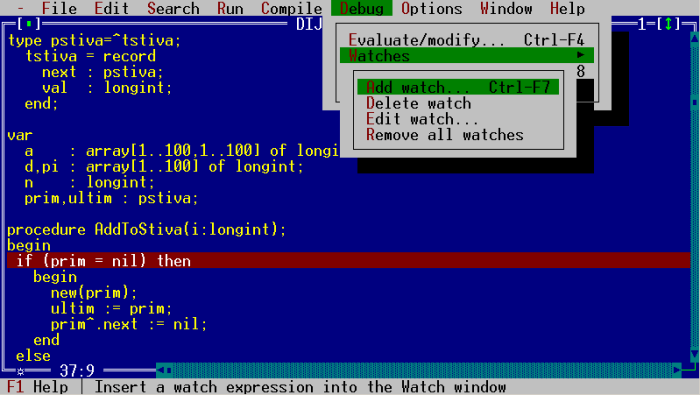
The answer to providing a modicum of security for interpreted applications has to this point been obfuscation – making the code look different so it can be difficult to decompile and figure out. Obfuscation used to mean padding the code with extra variables and gibberish – that is until a company in Cleveland, Ohio, called Preemptive Solutions Inc. came out with a bytecode optimizer for Java. Called DashO, this software was intended to make Java programs load and run faster by removing all code that wasn’t necessary, which is to say de-obfuscating and making perfectly clear what had been so carefully muddied before.
Preemptive also makes Dotfuscator for the .NET market. A “community edition” of this obfuscator was included with VS.NET 2003. Microsoft knew they had a thorny problem on their hands – balancing the utility of source code access with the legitimate need to protect commercial software.
I believe you can attribute much of .NET’s success to its transparency; it’s free, easy to obtain, easy to write, and easy to reverse engineer. I’ve read dozens of blog posts where authors successfully decompiled Microsoft .NET libraries to diagnose difficult problems. .NET’s openness is also an indirect compliment to the open source movement, where “security through obscurity” is a derogatory slur.
On the other hand, there are special conditions where you do need some additional security. Why pay for a component when you can download it, easily decompile it, and comment out the trial restrictions? If I was selling a commercial .NET component, I’d be a fool to release a trial version without obfuscating it first. As with all client-side protection methods, this is only a stopgap intended to raise the difficulty bar. But it’s still worth doing. I lock the front door of my house, too. Right after I activate my nuclear-powered laser attack robots.
I believe it’s best to err on the side of transparency. That buys you a lot more in the long run. You’ll want to leverage basic “locking the front door” efforts, such as obfuscation, to keep cracking your licensing code from being a trivial one-click operation. But don’t expend a lot of additional effort on protecting your code – all client-side protection mechanisms are vulnerable by definition. Instead, keep improving and refining your code. You’re a lot more likely to beat would-be pirates through frequent, meaningful updates than you are by bothering your customers with increasingly onerous security measures.
One alternate solution is to write code in languages that are already obfuscated,* as demonstrated in the International Obfuscated C Code Contest. Here are two winning entries from 2004. Note that this is actual source code you’re viewing!


Or, for ultimate obfuscation, you can opt to write all your code in whitespace language.
*I kid! Or maybe not.