
The Infinite Version
One of the things I like most about Google’s Chrome web browser is how often it is updated. But now that Chrome has rocketed through eleven versions in two and a half years, the thrill of seeing that version number increment has largely worn off. It seems they’ve picked off all the low hanging fruit at this point and are mostly polishing. The highlights from Version 11, the current release of Chrome?
HTML5 Speech Input API. Updated icon.
Exciting, eh? Though there was no shortage of hand-wringing over the new icon, of course.
Chrome’s version number has been changing so rapidly lately that every time someone opens a Chrome bug on a Stack Exchange site, I have to check my version against theirs just to make sure we’re still talking about the same software. And once – I swear I am not making this up – the version incremented while I was checking the version.
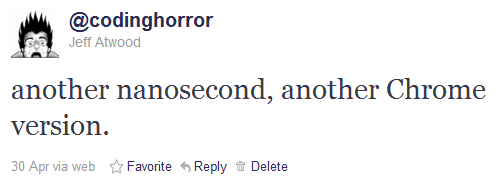
That was the day I officially stopped caring what version Chrome is. I mean, I care in the sense that sometimes I need to check its dog tags in battle, but as a regular user of Chrome, I no longer think of myself as using a specific version of Chrome, I just… use Chrome. Whatever the latest version is, I have it automagically.
For the longest time, web browsers have been strongly associated with specific versions. The very mention of Internet Explorer 6 or Netscape 4.77 should send a shiver down the spine of any self-respecting geek. And for good reason! Who can forget what a breakout hit Firefox 3 was, or the epochs that Internet Explorer 7, 8 and 9 represent in Microsoft history. But Chrome? Chrome is so fluid that it has transcended software versioning altogether.

This fluidity is difficult to achieve for client software that runs on millions of PCs, Macs, and other devices. Google put an extreme amount of engineering effort into making the Chrome auto-update process “just work.” They’ve optimized the heck out of the update process.
Rather then push put a whole new 10MB update [for each version], we send out a diff that takes the previous version of Google Chrome and generates the new version. We tried several binary diff algorithms and have been using bsdiff up until now. We are big fans of bsdiff – it is small and worked better than anything else we tried.
But bsdiff was still producing diffs that were bigger than we felt were necessary. So we wrote a new diff algorithm that knows more about the kind of data we are pushing – large files containing compiled executables. Here are the sizes for the recent 190.1 -> 190.4 update on the developer channel:
- Full update: 10 megabytes
- bsdiff update: 704 kilobytes
- Courgette update: 78 kilobytes
The small size in combination with Google Chrome’s silent update means we can update as often as necessary to keep users safe.
Google’s Courgette – the French word for Zucchini, oddly enough – is an amazing bit of software optimization, capable of producing uncannily small diffs of binary executables. To achieve this, it has to know intimate details about the source code:
The problem with compiled applications is that even a small source code change causes a disproportional number of byte level changes. When you add a few lines of code, for example, a range check to prevent a buffer overrun, all the subsequent code gets moved to make room for the new instructions. The compiled code is full of internal references where some instruction or datum contains the address (or offset) of another instruction or datum. It only takes a few source changes before almost all of these internal pointers have a different value, and there are a lot of them - roughly half a million in a program the size of chrome.dll.
The source code does not have this problem because all the entities in the source are symbolic. Functions don’t get committed to a specific address until very late in the compilation process, during assembly or linking. If we could step backwards a little and make the internal pointers symbolic again, could we get smaller updates?
Since the version updates are relatively small, they can be downloaded in the background. But even Google hasn’t figured out how to install an update while the browser is running. Yes, there are little alert icons to let you know your browser is out of date, and you eventually do get nagged if you are woefully behind, but updating always requires the browser to restart.
Web applications have it far easier, but they have version delivery problems, too. Consider WordPress, one of the largest and most popular webapps on the planet. We run WordPress on multiple blogs and even have our own WordPress community. WordPress doesn’t auto-update to each new version, but it makes it as painless as I’ve seen for a webapp. Click the update link on the dashboard and WordPress (and its add-ons) update to the latest version all by themselves. There might be the briefest of interruptions in service for visitors to your WordPress site, but then you’re back in business with the latest update.
WordPress needs everyone to update to the latest versions regularly for the same reasons Google Chrome does – security, performance, and stability. An internet full of old, unpatched WordPress or Chrome installations is no less dangerous than an internet full of old, unpatched Windows XP machines.
These are both relatively seamless update processes. But they’re nowhere near as seamless as they should be. One click updates that require notification and restart aren’t good enough. To achieve the infinite version, we software engineers have to go a lot deeper.

Somehow, we have to be able to automatically update software while it is running without interrupting the user at all. Not if – but when – the infinite version arrives, our users probably won’t even know. Or care. And that’s how we’ll know we’ve achieved our goal.



