.net
Donating $5,000 to .NET Open Source
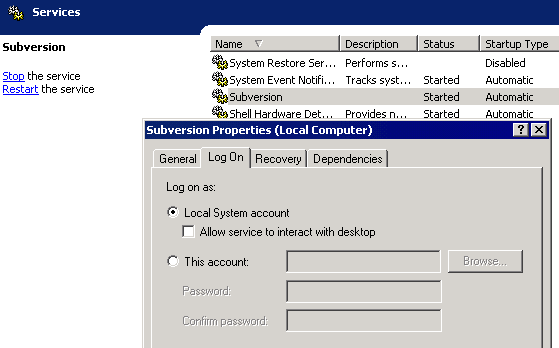
Way back in June of last year, I promised to donate a portion of my advertising revenue back to the community: I will be donating a significant percentage of my ad revenue back to the programming community. The programming community is the reason I started this blog in the first