In Reducing Your Website's Bandwidth Usage, I concluded that my best outsourced image hosting option was Amazon's S3 or Simple Storage Service.
S3 is a popular choice for startups. For example, SmugMug uses S3 as their primary data storage source. There have been a few minor S3-related bumps at SmugMug, but overall the prognosis appears to be good. After experimenting with S3 myself, I'm sold. The costs are reasonable:
- No start up fees, no minimum charge
- $0.15 per GB for each month of storage
- $0.20 per GB of data transferred
It's not exactly unlimited bandwidth, but I was planning to spend $2 a month on image hosting anyway. That buys me 10 GB per month of highly reliable, pure file transfer bandwidth through S3. Beyond that, it's straight pay-as-you-go.
Unfortunately, Amazon doesn't provide a GUI or command-line application for easily transferring files to S3; it's only a set of SOAP and REST APIs.
There is Jungle Disk, which allows S3 to show up as a virtual drive on your computer, but Jungle Disk offers no way to make files accessible through public HTTP. And as I found out later, Jungle Disk also uses a strange, proprietary file naming and storage structure on S3 when you view it directly. Jungle Disk is a fine backup and offline storage tool (particularly considering how cheap S3 disk storage costs are), but it doesn't offer the level of control that I need.
Amazon does provide a number of API code samples in various languages, along with some links to tutorial articles, but beyond that, you're basically on your own. Or so I thought.
That was before I found the S3Fox Organizer for FireFox.
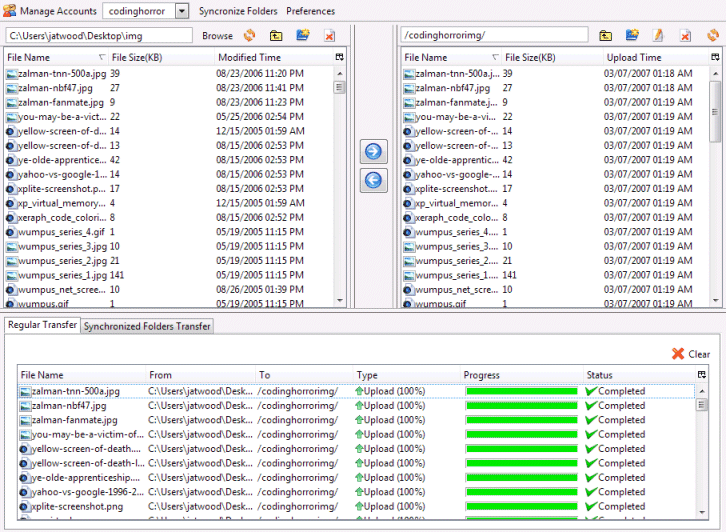
S3Fox is like a dream come true after futzing around with the S3 API. Using S3Fox, I can easily experiment with the S3 service to figure out how it works instead of spending my time struggling with arcane S3 API calls in a development environment. It's a shame Amazon doesn't offer a tool like this to help people understand what the S3 service is and how it works.
At any rate, my goal is to use S3 as an image hosting service. I started by uploading an entire folder of images with S3Fox. I had a few problems where S3Fox would mysteriously fail in the middle of a transfer, forcing me to exit all the way out of Firefox. Fortunately, S3Fox also has folder synchronization support, so I simply restarted the entire transfer and told it to skip all files that were already present in S3. After a few restarts, all the files were successfully uploaded. I then granted anonymous access to the entire folder and all of its contents. This effectively exposed all the uploaded images through the public S3 site URL:
http://s3.amazonaws.com/
All S3 content has to go in what Amazon calls a "Bucket". Bucket names must be globally unique, and you can only create a maximum of 100 Buckets per account. It's easy to see why when you form the next part of the URL:
http://s3.amazonaws.com/codinghorrorimg/
Each Bucket can hold an unlimited number of "Objects" of essentially unlimited size, with as much arbitrary key-value pair metadata as you want attached. Objects default to private access, but they have explicit access control lists (for Amazon accounts only), and you can make them public. Once we've added an Object, if we grant public read permission to it, we can then access it via the complete site / Bucket / Object URL:
http://s3.amazonaws.com/codinghorrorimg/codinghorror-bandwidth-usage.png
There's no concept of folders in S3. You can only emulate folder structures by adding Objects with tricky names like subfolder/myfile.txt. And you can't rename Buckets or Objects, as far as I can tell. But at least I can control the exact filenames, which I was unable to do with any other image hosting service.
In my testing I ended up uploading the entire contents of my /images folder twice. That cost me a whopping two cents according to my real-time S3 account statement:
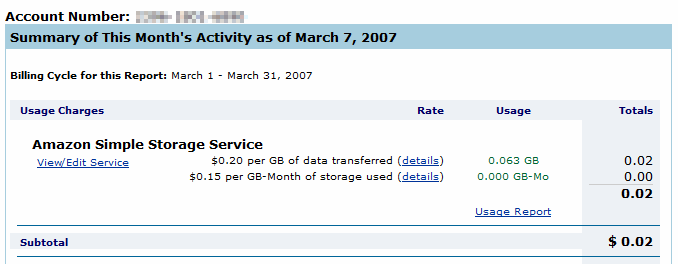
It's almost like micropayments in action.
S3 will probably end up costing me slightly more than the "Unlimited" $25/year accounts available on popular personal photo sharing sites. With S3, there's no illusion of unlimited bandwidth use unconstrained by cost. And personal photo and image sharing sites are often blocked by corporate networks, which makes sense if you consider their intended purpose: informally sharing personal photos. S3 is a more professional image hosting choice; it offers tighter control along with a full set of developer APIs.
Discussion
 Curly: Do you know what the secret of life is?
Curly: Do you know what the secret of life is?