Markdown was one of the humane markup languages that we evaluated and adopted for Stack Overflow. I've been pretty happy with it, overall. So much so that I wanted to implement a tiny, lightweight subset of Markdown for comments as well.
I settled on these three commonly used elements:
*italic* or _italic_ **bold** or __bold__ `code`
I loves me some regular expressions and this is exactly the stuff regex was born to do! It doesn't look very tough. So I dusted off my copy of RegexBuddy and began.
I typed some test data in the test window, and whipped up a little regex in no time at all. This isn't my first time at the disco.
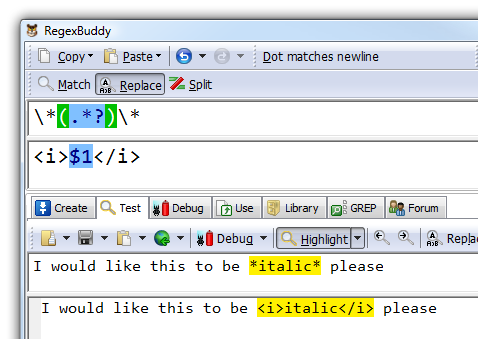
Bam! Yes! Done and done! By gum, I must be a genius programmer!
Despite my obvious genius, I began to have some small, nagging doubts. Is the test phrase...
I would like this to be *italic* please.
... really enough testing?
Sure it is! I can feel in my bones that this thing freakin' works! It's almost like I'm being pulled toward shipping this code by some inexorable, dark, testing ... force. It's so seductively easy!

But wait. I have this whole database of real world comments that people have entered on Stack Overflow. shouldn't I perhaps try my awesome regular expression on that corpus of data to see what happens? Oh, fine. If we must. Just to humor you, nagging doubt. Let's run a query and see.
select Text from PostComments where dbo.RegexIsMatch(Text, '*(.*?)*') = 1
Which produced this list of matches, among others:
Interesting fact about math: x * 7 == x + (x * 2) + (x * 4), or x + x >> 1 + x >> 2. Integer addition is usually pretty cheap.Thanks. What I needed was to turn on Singleline mode too, and use .*? instead of .*.
yeah, see my edit - change select * to select RESULT.* one row - are sure you have more than one row item with the same InstanceGUID?
Not your main problem, but you are mix and matching wchar_t and TCHAR. mbstowcs() converts from char * to wchar_t *.
aawwwww.... Brainf**k is not valid. :/
Thank goodness I listened to my midichlorians and let the light side of the testing force prevail here!

So how do we fix this regex? We use the light side of the force -- brute force, that is, against a ton of test cases! My job here is relatively easy because I have over 20,000 test cases sitting in a database. You may not have that luxury. Maybe you'll need to go out and find a bunch of test data on the internet somewhere. Or write a function that generates random strings to feed to the routine, also known as fuzz testing.
I wanted to leave the rest of this regular expression as an exercise for the reader, as I'm a sick guy who finds that sort of thing entertaining. If you don't -- well, what the heck is wrong with you, man? But I digress. I've been criticized for not providing, you know, "the answer" in my blog posts. Let's walk through some improvements to our italic regex pattern.
First, let's make sure we have at least one non-whitespace character inside the asterisks. And more than one character in total so we don't match the ** case. We'll use positive lookahead and lookbehind to do that.
*(?=S)(.+?)(?<=S)*
That helps a lot, but we can test against our data to discover some other problems. We get into trouble when there are unexpected characters in front of or behind the asterisks, like, say, p*q*r. So let's specify that we only want certain characters outside the asterisks.
(?<=[s^,(])*(?=S)(.+?)(?<=S)*(?=[s$,.?!])
Run this third version against the data corpus, and wow, that's starting to look pretty darn good! There are undoubtedly some edge conditions, particularly since we're unlucky enough to be talking about code in a lot of our comments, which has wacky asterisk use.
This regex doesn't have to be (and probably cannot be, given the huge possible number of human inputs) perfect, but running it against a large set of input test data gives me reasonable confidence that I'm not totally screwing up.
So by all means, test your code with the force -- brute force! It's good stuff! Just be careful not to get sloppy, and let the dark side of the testing force prevail. If you think one or two simple test cases covers it, that's taking the easy (and most likely, buggy and incorrect) way out.