
Mixing Oil and Water: Authorship in a Wiki World
When you visit Wikipedia’s entry on asphalt, you get some reasonably reliable information about asphalt. What you don’t get, however, is any indication of who the author is. That’s because the author is irrelevant. Wikipedia is a community effort, the result of tiny slices of effort contributed by millions of people around the world. The focus is on the value of the aggregated information, not who the individual authors are.
But who is that community? According to Jimmy Wales, most of the work on Wikipedia is done by a tightly knit Gang of 500:
Wales decided to run a simple study to find out: he counted who made the most edits to the site. “I expected to find something like an 80-20 rule: 80% of the work being done by 20% of the users, just because that seems to come up a lot. But it’s actually much, much tighter than that: it turns out over 50% of all the edits are done by just .7% of the users… 524 people… And in fact the most active 2%, which is 1400 people, have done 73.4% of all the edits.” The remaining 25% of edits, he said, were from “people who [are] contributing… a minor change of a fact or a minor spelling fix … or something like that.”
Stack Overflow has some wiki-like aspects, and even my limited experience with the genre tells me this claim is implausible. Aaron Swartz ran his own study and came to a very different conclusion:
I wrote a little program to go through each edit and count how much of it remained in the latest version. Instead of counting edits, as Wales did, I counted the number of letters a user actually contributed to the present article.
If you just count edits, it appears the biggest contributors to the Alan Alda article (7 of the top 10) are registered users who (all but 2) have made thousands of edits to the site. Indeed, #4 has made over 7,000 edits while #7 has over 25,000. In other words, if you use Wales’s methods, you get Wales’s results: most of the content seems to be written by heavy editors.
But when you count letters, the picture dramatically changes: few of the contributors (2 out of the top 10) are even registered and most (6 out of the top 10) have made less than 25 edits to the entire site. In fact, #9 has made exactly one edit – this one! With the more reasonable metric – indeed, the one Wales himself said he planned to use in the next revision of his study – the result completely reverses.
Insiders account for the vast majority of the edits. But it’s the outsiders who provide nearly all of the content.
Satisfying the needs of these two radically different audiences – the insiders and the outsiders – is the art of wiki design. That’s why, on Stack Overflow, we mix oil and water:
- There’s a strong sense of authorship, with a reputation system and a signature block attached to every post, like traditional blogs and forums.
- Once the system learns to trust you, you can edit anything – and we sometimes switch into a mode where authorship is de-emphasized to focus on the resulting content, like a wiki.
I’m not sure mixing these opposing elements would work for a project on the scale of Wikipedia. But I think it works for us (and when I say us, I mean programmers) because it’s analogous to the version control system baked into the DNA of every programmer. Communal ownership is all well and good, but sometimes you still need to know Who Wrote This Crap. Authorship matters, ownership matters – and yet there’s still something bigger, a larger goal we’re all working toward, that trumps any individual contribution we might make. Both elements are in play.
Still, we absorbed a lot of tension with this design choice, because authorship and wiki are fundamentally opposing goals. How do you balance self-interest (vote for me) with selflessness (vote for this content)? Sometimes it breaks down. There’s a rough area around the edges where these two systems meet. For example, consider the Stack Overflow question titled Significant new inventions in computing since 1980.
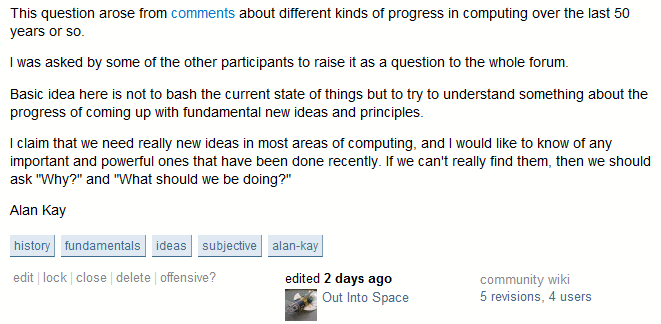
If you knew this question was from Turing Award winning computer scientist Alan Kay, would it change the way you reacted to it? Of course it would!
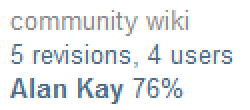
But you’d never know that, because our wiki signature block only tells you:
- The last editor (Out Into Space)
- How many revisions there have been to this question so far (5)
- How many users have created those revisions (4)
It’s a lot of information, by typical wiki standards. Who cares who wrote the question, as long as it’s a good question, right?
But that doesn’t entirely work; we also need to know who the primary author is, because that information will color and influence our responses to the question. I’ll grant you this is an extreme example; no disrespect to my fellow programmers, but you haven’t won a Turing award. Even in more typical cases, attaching authorship matters. It lets us know who we’re talking to, what their background is, what their skills are, and so forth. Furthermore, how can you possibly form a community when everyone is a random, anonymous contributor?
So the challenge, then, is tracking authorship – strictly for informational purposes – across a series of edit revisions. Jimbo erred in tracking only edit counts. Aaron used Python’s difflib.SequenceMatcher.find_longest_match to establish ownership across revisions. This is the basic technique visualized in IBM's History Flow.
Imagine a scenario where three people will make contributions to a Wiki page at different points in time. Each person edits the page and then saves their changes to what becomes the latest version of that page.
History Flow connects text that has been kept the same between consecutive versions. Pieces of text that do not have correspondence in the next (or previous) version are not connected and the user sees a resulting “gap” in the visualization; this happens for deletions and insertions.

It’s very cool when applied to larger inputs; see history flow visualization of the Wikipedia entry on evolution.
Now, the differencing of text is, in itself, not exactly a trivial problem. I started by examining the Levenshtein Distance, but this algorithm is truly brute force. See if you can tell why, in this visualization of the Levenshtein distance between “puzzle” and “pzzel”:
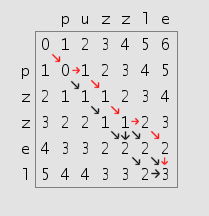
The levenshtein distance is a measure of how many insertions, deletions, or substitutions are required to transform string A into string B. The larger the number, the more different the strings are. We’re comparing two strings essentially letter-by-letter, which means the typical cost is O(mn), where m and n are the lengths of the two strings we’re comparing. That’s why you typically see Levenshtein used for comparing words, nothing on the order of paragraphs or pages.
I played around with Levenshtein for a while, but even optimized implementations are brutally slow as the size of the input increases. I quickly realized that a line-based comparison was the only workable one. We used this C# implementation of An O(ND) Difference Algorithm and its Variations (pdf).
What I ended up implementing was nowhere near as thorough as IBM’s history flow, although it’s probably similar to the rough metrics Aaron used. I simply sum the total size of all line contributions (insertions or deletions) from any given author in a revision, with a small bonus multiplier of 2x for the original author. We report the highest percentage of authorship in the final revision.
The line-based diff approach for determining authorship is far from perfect; it’d be more accurate if it was per-word or per-sentence. But it’s a fairly good approximation in my testing.
And most importantly, wiki posts by Alan Kay look like they’re from Alan Kay.




{kind=link}