Exception-Driven Development
If you’re waiting around for users to tell you about problems with your website or application, you’re only seeing a tiny fraction of all the problems that are actually occurring. The proverbial tip of the iceberg.

Also, if this is the case, I’m sorry to be the one to have to tell you this, but you kind of suck at your job – which is to know more about your application’s health than your users do. When a user informs me about a bona fide error they’ve experienced with my software, I am deeply embarrassed. And more than a little ashamed. I have failed to see and address the issue before they got around to telling me. I have neglected to crash responsibly.
The first thing any responsibly run software project should build is an exception and error reporting facility. Ned Batchelder likens this to putting an oxygen mask on yourself before you put one on your child:
When a problem occurs in your application, always check first that the error was handled appropriately. If it wasn’t, always fix the handling code first. There are a few reasons for insisting on this order of work:
- With the original error in place, you have a perfect test case for the bug in your error handling code. Once you fix the original problem, how will you test the error handling? Remember, one of the reasons there was a bug there in the first place is that it is hard to test it.
- Once the original problem is fixed, the urgency for fixing the error handling code is gone. You can say you’ll get to it, but what’s the rush? You’ll be like the guy with the leaky roof. When it’s raining, he can’t fix it because it’s raining out, and when it isn’t raining, there’s no leak!
You need to have a central place that all your errors are aggregated, a place that all the developers on your team know intimately and visit every day. On Stack Overflow, we use a custom fork of ELMAH.
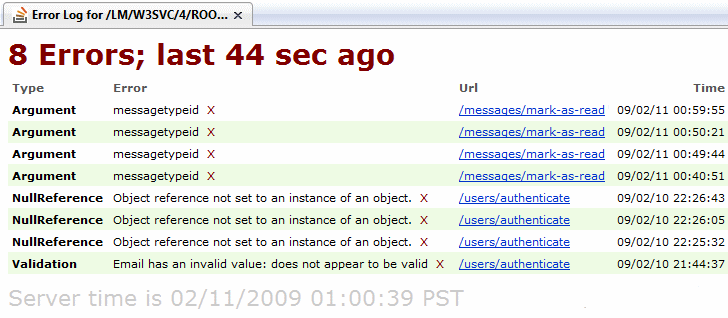
We monitor these exception logs daily; sometimes hourly. Our exception logs are a de-facto to do list for our team. And for good reason. Microsoft has collected similar sorts of failure logs for years, both for themselves and other software vendors, under the banner of their Windows Error Reporting service. The resulting data is compelling:
When an end user experiences a crash, they are shown a dialog box which asks them if they want to send an error report. If they choose to send the report, WER collects information on both the application and the module involved in the crash, and sends it over a secure server to Microsoft.
The mapped vendor of a bucket can then access the data for their products, analyze it to locate the source of the problem, and provide solutions both through the end user error dialog boxes and by providing updated files on Windows Update.
Broad-based trend analysis of error reporting data shows that 80% of customer issues can be solved by fixing 20% of the top-reported bugs. Even addressing 1% of the top bugs would address 50% of the customer issues. The same analysis results are generally true on a company-by-company basis too.
Although I remain a fan of test driven development, the speculative nature of the time investment is one problem I’ve always had with it. If you fix a bug that no actual user will ever encounter, what have you actually fixed? While there are many other valid reasons to practice TDD, as a pure bug fixing mechanism it’s always seemed far too much like premature optimization for my tastes. I’d much rather spend my time fixing bugs that are problems in practice rather than theory.
You can certainly do both. But given a limited pool of developer time, I’d prefer to allocate it toward fixing problems real users are having with my software based on cold, hard data. That’s what I call Exception-Driven Development. Ship your software, get as many users in front of it as possible, and intently study the error logs they generate. Use those exception logs to hone in on and focus on the problem areas of your code. Rearchitect and refactor your code so the top 3 errors can’t happen any more. Iterate rapidly, deploy, and repeat the process. This data-driven feedback loop is so powerful you’ll have (at least from the users’ perspective) a rock stable app in a handful of iterations.
Exception logs are possibly the most powerful form of feedback your customers can give you. It’s feedback based on shipping software that you don’t have to ask or cajole users to give you. Nor do you have to interpret your users’ weird, semi-coherent ramblings about what the problems are. The actual problems, with stack traces and dumps, are collected for you, automatically and silently. Exception logs are the ultimate in customer feedback.
Am I advocating shipping buggy code? Incomplete code? Bad code? Of course not. I’m saying that the sooner you can get your code out of your editor and in front of real users, the more data you’ll have to improve your software. Exception logs are a big part of that; so is usage data. And you should talk to your users, too. If you can bear to.
Your software will ship with bugs anyway. Everyone’s software does. Real software crashes. Real software loses data. Real software is hard to learn, and hard to use. The question isn’t how many bugs you will ship with, but how fast can you fix those bugs? If your team has been practicing exception-driven development all along, the answer is – why, we can improve our software in no time at all! Just watch us make it better!
And that is sweet, sweet music to every user’s ears.