I set up a number of Windows XP SP2 Virtual PC base images today. A WinXP SP2 clean install, after visiting Windows Update, is 1.70 gigabytes. Building up a few baseline images like this can chew up a substantial amount of disk space and network bandwidth. So, taking a page from Jon Galloway's book, I decided to see what I'd get if I compressed the virtual hard drive file. My results?
| App | Size | Time taken (approx)
|
| WinZip 9.0 SR-1 | 880 megabytes | 3 minutes
|
| 7Zip 4.20 | 739 megabytes | 22 minutes
|
(All apps were used with out of box defaults). I do end up with a file that is 17% smaller, but it takes 7.3 times longer. That sure doesn't seem like a very good deal to me. Now, in fairness to Jon, his only goal was to squeeze a largish 10gb VHD image into a single 4.7 gigabyte DVD-R; compression time wasn't a criteria.
Although this is my first exposure to 7zip, I've run these kinds of comparions before with ZIP and RAR and reached the same conclusion. Although there are certainly different algorithmic efficiencies, no matter what compression algorithm you choose-- beyond a certain optimal compression level, performance falls off a cliff. After you hit that point, you'll spend obscene amounts of time for rapidly diminishing benefits. Nowhere is this better illustrated than in Wim Heirman's Practical Compressor Test results:
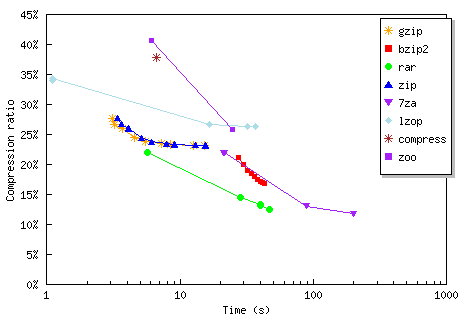
Note that the scale on the bottom of the graph is logarithmic. This is the only comparison I could find that properly expresses compression as the zero-sum game it really is: you can either have efficiency, or you can have speed. That's why, except for the truly obsolete algorithms, you see the "diagonal line" effect on this graph: better compression algorithms always take longer. Sometimes a lot longer. If you're holding out for Hyper Turbo Extreme Compression X algorithm, you may be waiting a while. Consider RAR, which offers the best blend of compression and speed currently available:
| Level | Time (secs) | Compression ratio | Time factor | Gain
|
| -m1 | 5.7 | 22.1% | 1x | -
|
| -m2 | 28.3 | 14.5% | 5x longer | 7.6% smaller
|
| -m3 | 40.2 | 13.4% | 7x longer | 8.7% smaller
|
| -m4 | 40.2 | 13.1% | 7x longer | 9.0% smaller
|
| -m5 | 46.7 | 12.5% | 8x longer | 9.6% smaller
|
When it takes 5 times longer for barely 8% more compression, you've fallen off a cliff. But it still might be worth the extreme cost, depending on your goals. For most usages, it boils down to these three questions:
- How often will your data be compressed?
- How many times will it be transferred?
- How fast is the network?
Decompression time in this scenario is usually a tiny, relatively constant fraction of the compression time, so it's not a factor. Wim provides a helpful calculator to assist in making this decision:
total time = compression time + n * (compressed file size / network speed + decompression time)
For instance, if you compress a file to send it over a network once, n equals one and compression time will have a big influence. If you want to post a file to be downloaded many times, n is big so long compression times will weigh less in the final decision. Finally, slow networks will do best with a slow but efficient algorithm, while for fast networks a speedy, possibly less efficient algorithm is needed.
Of course, there are still a few variables Wim's page hasn't considered. Most notably, he only compresses a single file (the GIMP source TAR file), which has two consequences:
- Filetype specific compression can perform far better than the generic compression considered here. Compression tailored to file contents (eg, lossless audio compression) is generally a huge win.
- When compressing groups of files, programs that can do "solid" archiving will always outperform those that can't. Solid archiving means that the files are compressed as one giant binary blob and not as a bunch of individual files. This provides a much higher level of overall compression due to (generally) repeated data between files.
No one set of benchmarks offers a complete picture. Most other compression benchmark pages tend to focus on absolute compression ratios to the detriment of all other variables, which is a little crazy once you've fallen off the cliff. On Wim's page, the slowest three times are 198 (7zip), 47 (rar), and 43 (bzip2) seconds respectively. Some of the more extreme space-optimized compression algorithms can take several hours to compress the same file!
Discussion