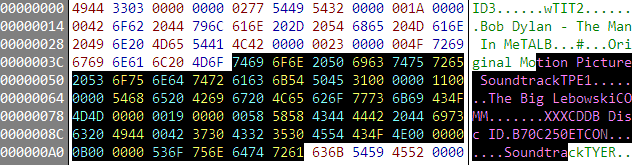
Although I always use CDDB metadata in my self-ripped MP3 files, the quality of the ID3 tags in my MP3 files lags far behind the quality of the file and folder names.
File and folder naming is immediately visible and easy to change.
C:MusicBeatlesThe White AlbumDisc 1�1 - Back in the USSR.mp3
Metadata tucked away inside a binary file.. isn't.
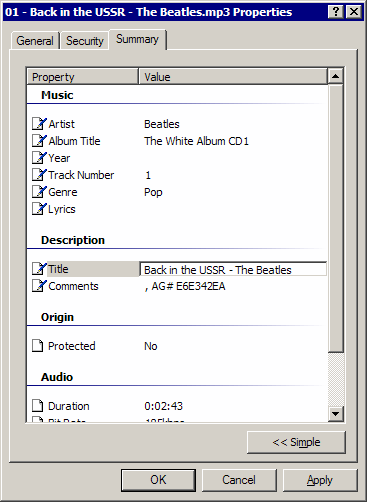
But Windows Media Player doesn't care a whit about my painstakingly constructed file names and folder trees. It ignores them completely in favor of the metadata inside the MP3 file to categorize music in its "media library". I've never used iTunes, but from what I've read, I understand it works the same way. To ignore obvious, simple external filesystem metadata in favor of complex internal ID3 metadata is doing a disservice to the user. But that's exactly how most media applications work!
It's also a case study in the difference between text and binary files. In the Googleland of web pages, everything is text, and therefore it's possible for everything to be self-describing and self-indexing. That's why Google ignores metadata on the web. Text files don't need metadata. Or even a filename. The words inside the text file describe it better than any human generally will. Human metadata is highly suspect; people aren't capable of creating objective metadata for their own content. Plus, there's money to be made, and a dozen other reasons the <meta> tag is all but irrelevant these days.
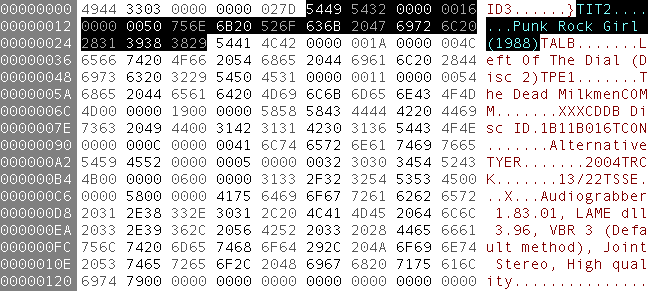
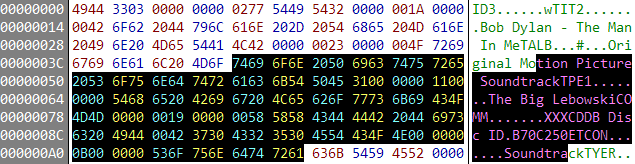
In the world of binary data-- music, pictures, and video-- there's no text inside the file to work with. For binary files, metadata isn't an optional nice to have. It's required. For example, when you perform a Google image search on "Wozniak", you're really searching the image metadata. If you get results, it's because..
- Some text near the image contains the word "wozniak"
- The alt tag for the image contains "wozniak"
- The filename for the image contains "wozniak"
Given how little metadata the image search has to work with, it's amazing that it works as well as it does..

.. but it still doesn't work very well. You just can't search binary content properly without structured metadata.
And that's why iTunes and Windows Media Player are so insistent about using the ID3 tags inside the MP3 files. Folders and filenames get awkward quickly. Everyone has a different organization method. One folder per Genre? Folders A-Z? One folder per Artist? Dashes, underscores, or semicolons for delimiters? Should filenames contain the information, or just the folders? Should the artist or the album come first? The larger your music library grows, the more unwieldy it is to organize using folders and filenames.
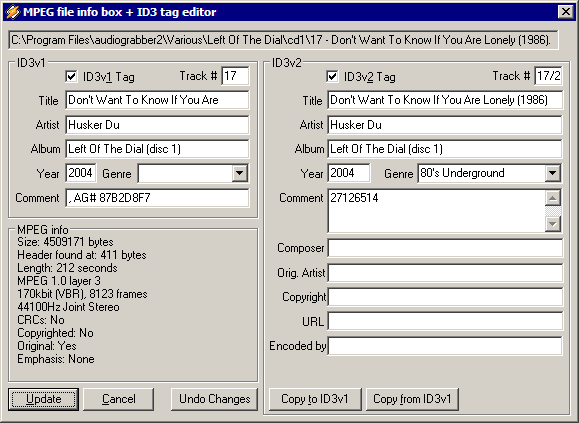
ID3 tags are more work, but they're far more effective. If you have proper ID3 tags, you can synthesize any file and folder structure you want. And searching your music collection is easy and fast, too.
That's why I've decided to buckle down and standardize all the ID3 tags in my MP3 collection. It's giant-- currently 10,970 songs and 733 albums in 48.9 gigabytes. I'm maniacal about ripping my own MP3 files with VBR encoding using Audiograbber and LAME. Proper ID3 tagging and album art also means my library will (finally) show up nicely in the music browser for my always-on, low-power optimized home theater PC running Windows Media Center.
Large hard drives have come down a lot in price, so it's now feasible to consolidate all my media storage on the HTPC with a single quiet 500gb data drive.
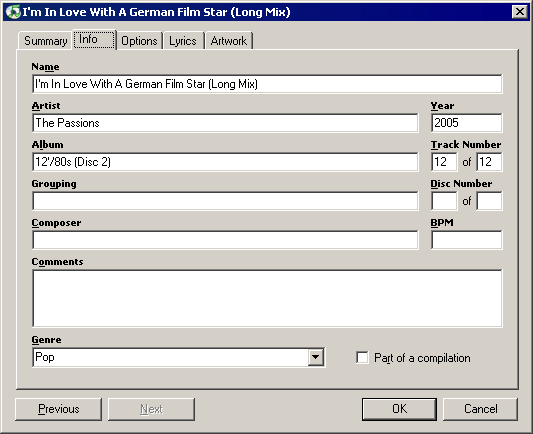
With this many songs to organize, going into a properties dialog for each file is clearly out of the question. The two ID3 tag organizing utilities I saw recommended most were Tag & Rename and MediaMonkey. I didn't get around to trying Tag & Rename, because I was blown away by how amazingly great MediaMonkey is. I can't recommend it strongly enough. The free version includes all the essential ID3 tag maintenance functions you'd ever need:
- An easy way to grab all album information from Amazon, including cover art, track details, year, and artist information.
- Flexible translation back and forth between filesystem metadata and ID3 metadata, with a real time "as you type" preview of what will happen. This is a killer feature!
- Visualize your library by folder or metadata to quickly find errors, typos, and miscategorizations. Then drag and drop to fix them.
- Built-in tools to fix common stuff like Title/Artist reversal (depressingly common), casing problems, duplicate content, etcetera.
- Designed for large music libraries. It's super fast at writing tags. It also queues updates intelligently; I did complete updates of 10,000+ tags several times.
It's an incredibly well-written app. It does everything right, including little stuff like automatic population of autocomplete drop-downs for every ID3 field based on your existing library. However, I do recommend switching to ASCII tags; it defaults to Unicode by default, which most people won't need, and this doubles the size of the tags.
Even with a great tool, fixing this much metadata was an incredibly tedious and thankless task. I don't even want to think about how much time I've spent on this. There's a lot of human error enshrined in the CDDB data:
- Track and Title reversed
- Spelling errors
- Grammar errors
- Casing problems; all lower case is common
- Missing important tags
Very few things in CDDB are totally wrong, however. If Wikipedia can work, so can CDDB (or something like it). It's a question of making the editing process as easy and obvious as possible, so these minor mistakes get fixed over time.
Beyond minor mistakes, metadata is a vast, grey wasteland of indeterminisms. Which of these is correct?
- "Eno, Brian" or "Brian Eno"?
- "Cardigans" or "The Cardigans"?
- "Earth Wind & Fire", or "Earth, Wind & File", or "Earth, Wind and Fire"?
- "Rock" or "Pop"?
- Does the Year field mean year of original song release or year of album release?
The correct answer is "all of the above". And then some.
Although I've been generally happy with the results of the ID3 tagging, there is one notable piece of ID3 metadata missing. I own lots of multi-disc sets. Unfortunately, there's no ID3 tag for disc number, eg, "Disc 3 of 12". I can't find any ID3 tag (at least, none that are visible in MediaMonkey) that looks appropriate. So I end up tacking the disc number on to the album title, which seems a little hokey. *
I suppose the true lesson here is that I should have been more diligent about editing metadata at the time I ripped the albums instead of deferring all the work until now. Trying to infer metadata through the filesystem seems like a workable solution, but it isn't. Filesystem metadata just doesn't scale.
* Update: this is the TPOS tag, and it's exposed in the UI for iTunes and Tag & Rename. It does not appear anywhere in MediaMonkey, which is an odd oversight.
Discussion