I recently imported some source code for a customer that exceeded the maximum path limit of 256 characters. The paths in question weren't particularly meaningful, just pathologically* long, with redundant subfolders. To complete the migration, I renamed some of the parent folders to single character values.
This made me wonder: is 256 characters a reasonable limit for a path? And what's the longest path in my filesystem, anyway? I whipped up this little C# console app to loop through all the paths on my drive and report the longest one.
static string _MaxPath = "";
static void Main(string[] args)
{
RecursePath(@"c:\");
Console.WriteLine("Maximum path length is " + _MaxPath.Length);
Console.WriteLine(_MaxPath);
Console.ReadLine();
}
static void RecursePath(string p)
{
foreach (string d in Directory.GetDirectories(p))
{
if (IsValidPath(d))
{
foreach (string f in Directory.GetFiles(d))
{
if (f.Length > _MaxPath.Length)
{
_MaxPath = f;
}
}
RecursePath(d);
}
}
}
static bool IsValidPath(string p)
{
if ((File.GetAttributes(p) & FileAttributes.ReparsePoint) == FileAttributes.ReparsePoint)
{
Console.WriteLine("'" + p + "' is a reparse point. Skipped");
return false;
}
if (!IsReadable(p))
{
Console.WriteLine("'" + p + "' *ACCESS DENIED*. Skipped");
return false;
}
return true;
}
static bool IsReadable(string p)
{
try
{
string[] s = Directory.GetDirectories(p);
}
catch (UnauthorizedAccessException ex)
{
return false;
}
return true;
}
It works, but it's a bit more complicated than I wanted it to be, because
- There are a few folders we don't have permission to access.
- Vista makes heavy use of reparse points to remap old XP folder locations as symbolic links.
The longest path on a clean install of Windows XP is 152 characters.
c:\Documents and Settings\All Users\Application Data\Microsoft\Crypto\RSAS-1-5-18d42cc0c3858a58db2db37658219e6400_89e7e133-abee-4041-a1a7-406d7effde91
This is followed closely by a bunch of stuff in c:\WINDOWS\assembly\GAC_MSIL, which is a side-effect of .NET 2.0 being installed.
The longest path on a semi-clean install of Windows 8.1 is 273 characters:
c:\Users\wumpus-home\AppData\Local\Packages\WinStore_cw5n1h2txyewy\AC\Microsoft\Windows Store\Cache\0\0-Namespace-https???services.apps.microsoft.com?browse?6.2.9200-1?615?en-US?c?US?Namespace?pc?00000000-0000-0000-0000-000000000000?00000000-0000-0000-0000-000000000000.
The longest path Microsoft created in Windows 8.1 is 273 characters. But what's the longest path I can create in Windows Explorer?
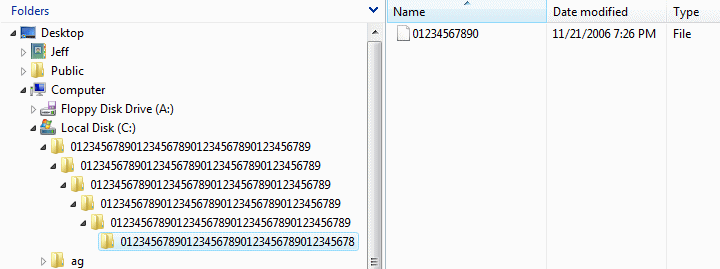
The best I could do is 239 characters for folders, and 11 characters for the filename. Add in 3 characters for the inevitable "c:", plus 6 slashes. That's a grand total of 259 characters. Anything longer and I got a "destination path too long" error.
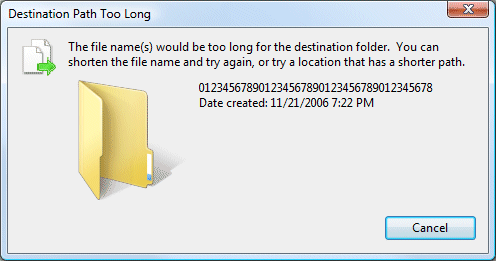
The 259 character path limit I ran into jibes with the documented MAX_PATH limitation of the Windows shell:
The maximum length path (in characters) that can be used by the [Windows] shell is
MAX_PATH(defined as 260). Therefore, you should create buffers that you will pass to SHFILEOPSTRUCT to be of lengthMAX_PATH+ 1 to account for these NULLs.
If 259 characters plus a null seems like an unusually restrictive path limit for a modern filesystem like NTFS, you're right. The NTFS filesystem supports paths of 32,000 characters, but it's largely irrelevant because the majority of Windows APIs you'd use to get to those paths only accept paths of MAX_PATH or smaller. There is a wonky Unicode workaround to the MAX_PATH limitation, according to MSDN:
In the Windows API (with some exceptions discussed in the following paragraphs), the maximum length for a path is
MAX_PATH, which is defined as 260 characters. A local path is structured in the following order: drive letter, colon, backslash, name components separated by backslashes, and a terminating null character. For example, the maximum path on drive D is "D:\some 256-character path string<NUL>" where "<NUL>" represents the invisible terminating null character for the current system codepage. (The characters < > are used here for visual clarity and cannot be part of a valid path string.)The Windows API has many functions that also have Unicode versions to permit an extended-length path for a maximum total path length of 32,767 characters. This type of path is composed of components separated by backslashes, each up to the value returned in the lpMaximumComponentLength parameter of the GetVolumeInformation function (this value is commonly 255 characters). To specify an extended-length path, use the "\?" prefix. For example, "\?\D:\very long path".
The "\?" prefix can also be used with paths constructed according to the universal naming convention (UNC). To specify such a path using UNC, use the "\?\UNC" prefix. For example, "\?\UNC\server\share", where "server" is the name of the computer and "share" is the name of the shared folder. These prefixes are not used as part of the path itself. They indicate that the path should be passed to the system with minimal modification, which means that you cannot use forward slashes to represent path separators, or a period to represent the current directory, or double dots to represent the parent directory. Because you cannot use the "\?" prefix with a relative path, relative paths are always limited to a total of
MAX_PATHcharacters.The shell and the file system may have different requirements. It is possible to create a path with the API that the shell UI cannot handle.
Still, I wonder if the world really needs 32,000 character paths. Is a 260 character path really that much of a limitation? Do we need hierarchies that deep? Martin Hardee has an amusing anecdote on this topic:
We were very proud of our user interface and the fact that we had a way to browse 16,000 (!!) pages of documentation on a CD-ROM. But browsing the hierarchy felt a little complicated to us. So we asked Tufte to come in and have a look, and were hoping perhaps for a pat on the head or some free advice.
He played with our AnswerBook for about 90 seconds, turned around, and pronounced his review:
"Dr Spock's Baby Care is a best-selling owner's manual for the most complicated 'product' imaginable – and it only has two levels of headings. You people have 8 levels of hierarchy and I haven't even stopped counting yet. No wonder you think it's complicated."
I think 260 characters of path is more than enough rope to hang ourselves with. If you're running into path length limitations, the real problem isn't the operating system, or even the computers. The problem is the deep, dark pit of hierarchies the human beings have dug themselves into.
* ouch
Discussion