
Beyond RAID
I’ve always been leery of RAID on the desktop. But on the server, RAID is a definite must:
“RAID” is now used as an umbrella term for computer data storage schemes that can divide and replicate data among multiple hard disk drives. The different schemes/architectures are named by the word RAID followed by a number, as in RAID 0, RAID 1, etc. RAID’s various designs all involve two key design goals: increased data reliability or increased input/output performance. When multiple physical disks are set up to use RAID technology, they are said to be in a RAID array. This array distributes data across multiple disks, but the array is seen by the computer user and operating system as one single disk.
I hadn’t worked much at all with RAID, as I felt the benefits did not outweigh the risks on the desktop machines I usually build. But the rules are different in the datacenter; the servers I built for Stack Overflow all use various forms of RAID, from RAID 1 to RAID 6 to RAID 10. While working with these servers, I was surprised to discover there are now umpteen zillion numbered variants of RAID – but they all appear to be based on a few basic, standard forms:
RAID 0: Striping
Data is striped across (n) drives, which improves performance almost linearly with the number of drives, but at a steep cost in fault tolerance; a failure of any single striped drive renders the entire array unreadable.
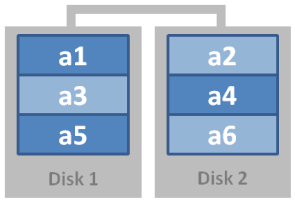
RAID 1: Mirroring
Data is written across (n) drives, which offers near-perfect redundancy at a slight performance decrease when writing – and at the cost of half your overall storage. As long as one drive in the mirror array survives, no data is lost.
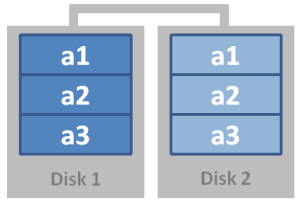
Raid 5: Parity
Data is written across (n) drives with a parity block. The array can tolerate one drive failure, at the cost of one drive in storage. There may be a serious performance penalty when writing (as parity and blocks are calculated), and when the array is rebuilding.
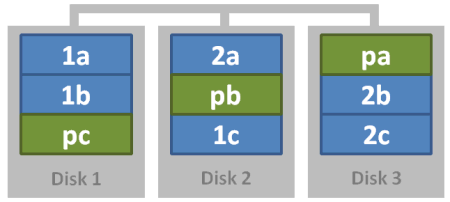
Raid 6: Dual Parity
Data is written across (n) drives with two parity blocks. The array can tolerate two drive failures, at the cost of two drives in storage. There may be a serious performance penalty when writing (as parity and blocks are calculated), and when the array is rebuilding.
(yes, there are other forms of RAID, but they are rarely implemented or used as far as I can tell.)
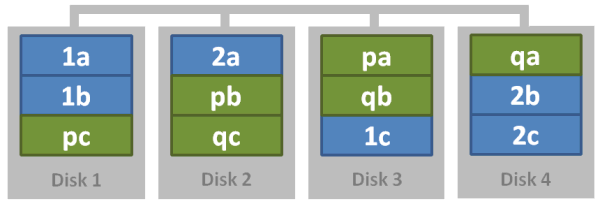
It’s also possible to generate so-called RAID 10 or RAID 50 arrays by nesting these RAID levels together. If you take four hard drives, stripe the two pairs, then mirror the two striped arrays – why, you just created yourself a magical RAID 10 concoction! What’s particularly magical about RAID 10 is that it inherits the strengths of both of its parents: mirroring provides excellent redundancy, and striping provides excellent speed. Some would say that RAID 10 is so good it completely obviates any need for RAID 5, and I for one agree with them.
This was all fascinating new territory to me; I knew about RAID in theory but had never spent hands-on time with it. The above is sufficient as a primer, but I recommend reading through the Wikipedia entry on RAID for more depth.
It’s worth mentioning here that RAID is in no way a substitute for a sane backup regimen, but rather a way to offer improved uptime and survivability for your existing systems. Hard drives are cheap and getting cheaper every day – why not use a whole slew of the things to get better performance and better reliability for your servers? That’s always been the point of Redundant Array of Inexpensive Disks, as far as I’m concerned. I guess Sun agrees; check out this monster:

That’s right, 48 commodity SATA drives in a massive array, courtesy of the Sun Sunfire X4500. It also uses a new RAID system dubbed RAID-Z:
RAID-Z is a data/parity scheme like RAID-5, but it uses dynamic stripe width. Every block is its own RAID-Z stripe, regardless of block size. This means that every RAID-Z write is a full-stripe write. This, when combined with the copy-on-write transactional semantics of ZFS, completely eliminates the RAID write hole. RAID-Z is also faster than traditional RAID because it never has to do read-modify-write.
But far more important, going through the metadata means that ZFS can validate every block against its 256-bit checksum as it goes. Traditional RAID products can’t do this; they simply XOR the data together blindly.
Which brings us to the coolest thing about RAID-Z: self-healing data. In addition to handling whole-disk failure, RAID-Z can also detect and correct silent data corruption. Whenever you read a RAID-Z block, ZFS compares it against its checksum. If the data disks didn’t return the right answer, ZFS reads the parity and then does combinatorial reconstruction to figure out which disk returned bad data. It then repairs the damaged disk and returns good data to the application. ZFS also reports the incident through Solaris FMA so that the system administrator knows that one of the disks is silently failing.
Finally, note that RAID-Z doesn’t require any special hardware. It doesn’t need NVRAM for correctness, and it doesn’t need write buffering for good performance. With RAID-Z, ZFS makes good on the original RAID promise: it provides fast, reliable storage using cheap, commodity disks.
Pardon the pun, but I’m not sure if it makes traditional hardware RAID redundant, necessarily. Even so, there are certainly fantastic, truly next-generation ideas in ZFS. There’s a great ACM interview with the creators of ZFS that drills down into much more detail. Hard drives may be (mostly) dumb hunks of spinning rust, but it’s downright amazing what you can do when you get a whole bunch of them working together.






