The anecdote that best reveals how little Stinky knew about programming started when he asked Bojan to help him solve the following problem:
"I have a function that returns Boolean value. Well, I would like to call that function and store the opposite value in some variable. I could code it like this: If function = true Then variable = false Else variable = true. But I have a feeling that it can be even simpler than that. Can you tell me how?"
After Bojan recovered from the shock of realizing that Stinky didn't know the basics of logical algebra, he replied that it was enough to put variable = Not function. Stinky went to check it out and after few minutes he cheerfully shouted: "It works!". Bartol was a witness to the whole scene. A few moments later he said to Bojan, "You see, my friend, to hell with education, your degree in computer science and the tons of books you read. You don't need any of that to be a champion developer like Stinky. Just learn the copy-paste method, remember all the properties of Janus Gridex and ActiveBar control, and the world is yours."
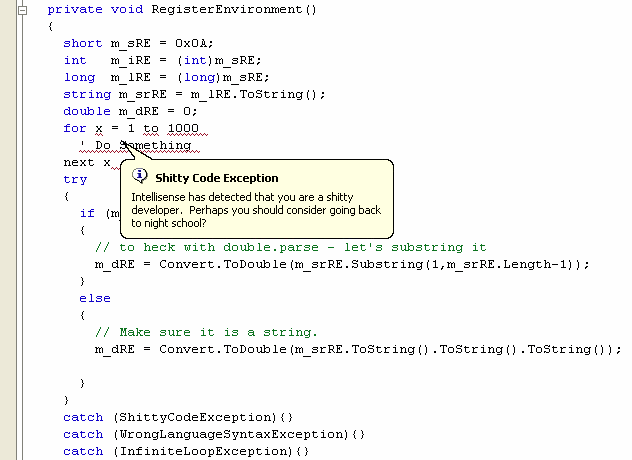
Sure, Microsoft's Office Assistant, Clippy, gets a lot of flak-- but wouldn't it be nice if Clippy could assist Stinky with his code?
Or, if the IDE could detect this kind of code as it's being typed and offer some helpful advice* to Stinky?
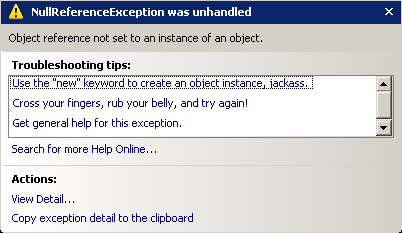
VS.NET 2005 also offers just-in-time intellisense for exceptions, which can be customized by editing the underlying XML. The intellisense for a NullReferenceException isn't very helpful for a developer like Stinky; here's one way K. Scott Allen improved it:
* Despite extensive use of my google-fu, I couldn't find the original source of this image. If anyone knows who originally created it, let me know so I can attribute it properly.
"419 is just a game, you are the losers, we are the winners.
White people are greedy, I can say they are greedy
White men, I will eat your dollars, will take your money and disappear.
419 is just a game, we are the masters, you are the losers."
We may joke about the 419 scams.. after all, who in their right mind actually falls for this stuff? But like all spammers, they do it because it works:
[Samuel] sent 500 e-mails a day and usually received about seven replies. Shepherd would then take over. "When you get a reply, it's 70% sure that you'll get the money," Samuel said.
Spam only became a problem for me about a year and a half ago, but clearly it's here to stay. I've used POPFile for about a year to cut down on my email spam**. Some people swear by challenge-response human verification systems such as SpamArrest, but as Scott Mitchell notes, this system has some issues:
While the challenge/response system was effective in reducing my spam intake from about 100 messages a day to around 1 or 2 messages a day, the approach, in my estimation, was not ideal. One big disadvantage was that fewer people took the time to respond to the challenge email than I had anticipated, for two reasons:
Some people don't want to take the time to follow instructions for a challenge email. Maybe their message wasn't that important after all, maybe they're busy, or maybe they just don't like being told what to do. These people's messages, I reckoned, weren't that vital. If you can't take two seconds to respond to the challenge, then just how important is that email you're sending me?
What worried me most, and led me to suspend my C/R anti-spam system, is that I noticed some people weren't responding to the challenge email because they never received it! This unfortunate circumstance could happen if their own spam blocking solution halted my challenge email. A couple folks informed me that Outlook 2003 categorized my challenge emails as spam. Others using a similar challenge/response anti-spam system would never get my challenge as my challenge would generate a challenge on their side.
Although I've had great success with POPFile, which uses Bayesian filtering techniques, I had no idea that there's an even better technique: Markovian filtering. That's what the CRM114 Discriminator* uses. There's an outstanding slide deck (pdf) that explains how it all works. In a nutshell, Markovian filtering weights phrases and words, whereas Bayesian filtering only looks at individual words. How much better is it? I'll let the CRM114 author, Bill Yerazunis, pitch it:
For the month of April 2005, I receieved over 10,000 emails. About 60% were spam. I had ZERO classification errors. ZERO.
As of Feb 1 through March 1, 2004, 8738 messages (4240 spam, 4498 nonspam), and my total error rate was ONE. That translates to better than 99.984% accuracy, which is over ten times more accurate than human accuracy
I measured my own accuracy to be around 99.84%, by classifying the same set of about 3000 messages twice over a period of about a week, reading each message from the top until I feel "confident" of the message status, (one message per screen unless I want more than one screen to decide on a message.) and doing the classification in small batches with plenty of breaks and other office tasks to avoid fatigue. Then I diff()ed the two passes to generate a result. Assuming I never duplicate the same mistake, I, as an unassisted human, under nearly optimal conditions, am 99.84% accurate.
Most Bayesian techniques top out at around ~98% percent accuracy with a little training, but Markovian can achieve a rarified 99.5% accuracy. The most notable Windows port of CRM114 is SpamRIP.
* A reference to the movie Dr. Strangelove. In the movie, the "CRM114 Discriminator" is a fictional accessory for a radio receiver that's "designed not to receive at all", that is, unless the message is properly authenticated.
** I have since switched to K9 because it's simpler and faster-- and does the same Bayesian filtering.
The paging file (pagefile.sys) is a hidden system file that forms a key component of the Virtual Memory Manager (VMM) on Windows platforms. The origin of this file dates back to early 1990s when Windows ran on PC hardware that had limited physical memory due to the high cost of RAM and the limitations of motherboard design. (The concept of virtual memory itself, of course, is much older.) The purpose of the pagefile was to allow memory-hungry applications to circumvent insufficient RAM by allowing seldom-used pages of RAM to be swapped to disk until needed (hence the term swapfile used on earlier Windows platforms). For example, if a Windows 3.1 machine had 8MB of RAM and a 12MB permanent swap file (386spart.par) on its C: drive, then the effective memory that applications could use was 8 + 12 = 20MB.
This idea was indeed crazy in a world where 256mb, 512mb and 1gb of memory were the norm. Now that 2 gb of memory is relatively common, disabling the pagefile isn't such a crazy idea any more.
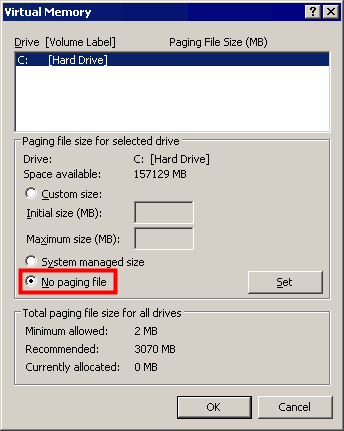
A number of developers are already running their systems with the pagefile disabled, as this post by Peter Provost illustrates. Clearly it works. I've been running this way for a few days, and I haven't encountered any issues yet.
However, I'm not so sure there's any practical performance increase from disabling your pagefile. If our systems were never running out of physical memory with 2gb, then theoretically the pagefile never gets used anyway. And disabling the pagefile also introduces a new risk: if an app requests more memory than is physically available, it will receive a stern "out of memory" error instead of the slow disk-based virtual memory the OS would normally provide. This Q&A outlines the risks:
So, if you have a lot of RAM, you don't need a pagefile, right? Not necessarily. When certain applications start, they allocate a huge amount of memory (hundreds of megabytes typically set aside in virtual memory) even though they might not use it. If no pagefile (i.e., virtual memory) is present, a memory-hogging application can quickly use a large chunk of RAM. Even worse, just a few such programs can bring a machine loaded with memory to a halt. Some applications (e.g., Adobe Photoshop) will display warnings on startup if no pagefile is present.
My advice, therefore, is not to disable the pagefile, because Windows will move pages from RAM to the pagefile only when necessary. Furthermore, you gain no performance improvement by turning off the pagefile. To save disk space, you can set a small initial pagefile size (as little as 100MB) and set a high maximum size (e.g., 1GB) so that Windows can increase the size if needed. With 1GB of RAM under normal application loads, the pagefile would probably never need to grow.
This is one case where the 32-bit process memory limit of 4 gigabytes -- which is really 2 gigabytes once you factor in the Windows kernel memory split -- works in our favor.
It's a great set of guidelines that I completely agree with. However, it is missing one humongous mistake: disabling comments. You don't have a blog until you allow public, two way communication between the author and the reader. And when I say communication, I mean it: the author has to actually read and even (gasp!) respond to the comments. Otherwise you're just publishing content, like every other newspaper since the printing press was invented. Meh.
Unfortunately, I'm guilty of a few of these mistakes, notably #2 and #5. And technically this post violates #3 as well, but I coudn't resist:
If you publish on many different topics, you're less likely to attract a loyal audience of high-value users. Busy people might visit a blog to read an entry about a topic that interests them. They're unlikely to return, however, if their target topic appears only sporadically among a massive range of postings on other topics. The only people who read everything are those with too much time on their hands (a low-value demographic).
I certainly regretted not having my picture on my blog when I went to PDC 2005 and belatedly realized it was virtually impossible for me to meet any other bloggers. I only recognized people who were already famous (eg, Don Box) or had pictures on their blogs (eg, Sara Ford). I know, duh.
I've certainly known companies that do "unit testing" and other crap they've read in books. Now, you can argue this point if you'd like, because I don't have hard data; all I have is my general intuition built up over my paltry 21 years of being a professional programmer.
[..] You should test. Test and test and test. But I've NEVER, EVER seen a structured test program that (a) didn't take like 100 man-hours of setup time, (b) didn't suck down a ton of engineering resources, and (c) actually found any particularly relevant bugs. Unit testing is a great way to pay a bunch of engineers to be bored out of their minds and find not much of anything. [I know -- one of my first jobs was writing unit test code for Lighthouse Design, for the now-president of Sun Microsystems.] You'd be MUCH, MUCH better offer hiring beta testers (or, better yet, offering bug bounties to the general public).
Let me be blunt: YOU NEED TO TEST YOUR DAMN PROGRAM. Run it. Use it. Try odd things. Whack keys. Add too many items. Paste in a 2MB text file. FIND OUT HOW IT FAILS. I'M YELLING BECAUSE THIS IS IMPORTANT.
Most programmers don't know how to test their own stuff, and so when they approach testing they approach it using their programming minds: "Oh, if I just write a program to do the testing for me, it'll save me tons of time and effort."
It's hard to completely disregard the opinion of a veteran developer shipping an application that gets excellent reviews. Although his opinion may seem heretical to the Test Driven Development cognoscenti, I think he has some valid points:
Some bugs don't matter. Extreme unit testing may reveal.. extremely rare bugs. If a bug exists but no user ever encounters it, do you care? If a bug exists but only one in ten thousand users ever encounters it, do you care? Even Joel Spolsky seems to agree on this point. Shouldn't we be fixing bugs based on data gathered from actual usage rather than a stack of obscure, failed unit tests?
Real testers hate your code. A unit test simply verifies that something works. This makes it far, far too easy on the code. Real testers hate your code and will do whatever it takes to break it-- feed it garbage, send absurdly large inputs, enter unicode values, double-click every button in your app, etcetera.
Users are crazy. Automated test suites are a poor substitute for real world beta testing by actual beta testers. Users are erratic. Users have favorite code paths. Users have weird software installed on their PCs. Users are crazy, period. Machines are far too rational to test like users.
While I think basic unit testing can complement formal beta testing, I tend to agree with Wil: the real and best testing occurs when you ship your software to beta testers. If unit test coding is cutting into your beta testing schedule, you're making a very serious mistake.