The Danger of Naïveté
In my previous post on shuffling, I glossed over something very important. The very first thing that came to mind for a shuffle algorithm is this:
for (int i = 0; i < cards.Length; i++)
{
int n = rand.Next(cards.Length);
Swap(ref cards[i], ref cards[n]);
}
It’s a nice, simple solution to the shuffling problem:
- Loop through each card in the deck.
- Swap the current card with another randomly chosen card.
At first blush, this seems like a perfectly reasonable way to shuffle. It’s simple, it’s straightforward, and the output looks correct. It’s the very definition of a naïve algorithm:
A naïve algorithm is a very simple solution to a problem. It is meant to describe a suboptimal algorithm compared to a “clever” (but less simple) algorithm. Naïve algorithms usually consume larger amounts of resources (time, space, memory accesses... ), but are simple to devise and implement.
An example of a naïve algorithm is bubble sort, which is only a few lines long and easy to understand, but has a O(n2) time complexity. A more “clever” algorithm is quicksort, which, although being considerably more complicated than bubble sort, has a O(n log n) average complexity.
But there’s a deep, dark problem with this naïve shuffling algorithm, a problem that most programmers won’t see. Do you see it? Heck, I had the problem explained to me and I still didn’t see it.
Watch what happens when I use this naïve shuffling algorithm to shuffle a three-card deck 600,000 times. There are 3! or 6 possible combinations in that deck. If the shuffle is working properly, we should see each combination represented around 100,000 times.

As you can see, 231, 213, and 132 are over-represented, and the other three possibilities are under-represented. The naïve shuffle algorithm is biased and fundamentally broken. Moreover, the bias isn’t immediately obvious; you’d have to shuffle at least a few thousand times to see real statistical evidence that things aren’t working correctly. It’s a subtle thing.
Usually, naïve algorithms aren’t wrong – just oversimplified and inefficient. The danger, in this case, is rather severe. A casual programmer would implement the naïve shuffle, run it a few times, see reasonably correct results, and move on to other things. Once it gets checked in, this code is a landmine waiting to explode.
Let’s take a look at the correct Knuth-Fisher-Yates shuffle algorithm.
for (int i = cards.Length - 1; i > 0; i--)
{
int n = rand.Next(i + 1);
Swap(ref cards[i], ref cards[n]);
}
Do you see the difference? I missed it the first time. Compare the swaps for a 3 card deck:
| Naïve shuffle | Knuth-Fisher-Yates shuffle |
rand.Next(3); rand.Next(3); rand.Next(3); | rand.Next(3); rand.Next(2); |
The naïve shuffle results in 33 (27) possible deck combinations. That’s odd, because the mathematics tell us that there are really only 3! or 6 possible combinations of a 3 card deck. In the KFY shuffle, we start with an initial order, swap from the third position with any of the three cards, then swap again from the second position with the remaining two cards.
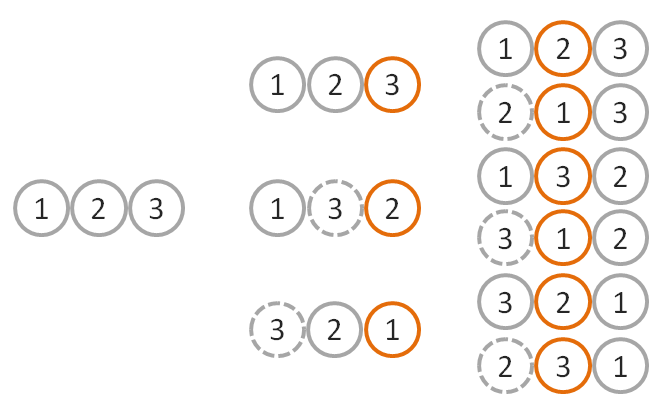
The KFY shuffle produces exactly 3 * 2 = 6 combinations, as pictured above. Based on your experience shuffling physical cards, you might think the more shuffling that goes on, the more random the deck becomes. But more shuffling results in worse, not better, results. That’s where the naïve algorithm goes horribly wrong. Let’s compare all possible permutations of a 3 card deck for each algorithm:
| Naïve shuffle | Knuth-Fisher-Yates shuffle | ||||||||||||
|
|
You can plainly see how some of the deck combinations appear unevenly in the 27 results of the naïve algorithm. Stated mathematically, 27 is not evenly divisible by six.
Enough theory. Let’s see more results. How about a four card deck, shuffled 600,000 times?
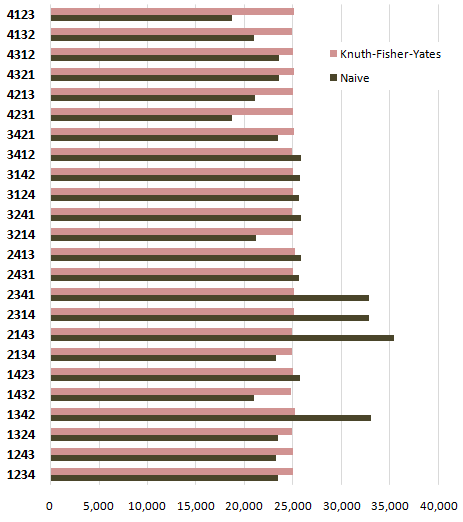
600,000 divided by 24 is 25,000; that’s almost exactly what we see right down the line for every possible combination of cards with the KFY shuffle algorithm. The naïve algorithm, in comparison, is all over the map.
It gets worse with larger decks. Here’s the same comparison for a six card deck.
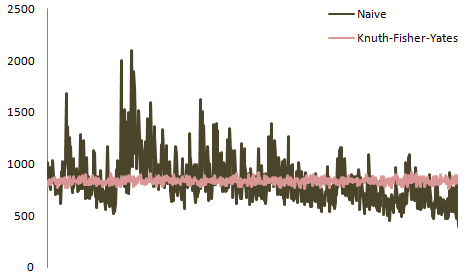
With a 6 card deck, the differences between the two algorithms grow even larger. The math, yet again, explains why.
6! = 720 66 = 46,656
With 46,656 paths to only 720 real world outputs, it’s inevitable that some of those paths will be severely over-represented or under-represented in the output. And are they ever. If you shipped a real card game with a naïve shuffle, you’d have some serious exploits to deal with.
I know this may seem like remedial math to some of you, but I found this result strikingly counterintuitive. I had a very difficult time understanding why the naïve shuffle algorithm, which is barely different from the KFY shuffle algorithm, produces such terribly incorrect results in practice. It’s a minute difference in the code, but a profound difference in results. Tracing through all the permutations and processing the statistics helped me understand why it was wrong.
Naïve implementations are often preferred to complex ones. Simplicity is a virtue. It’s better to be simple, slow, and understandable than complex, fast, and difficult to grasp. Or at least it usually is. Sometimes, as we’ve seen here with our shuffling example, the simplicity of the naïve implementation can mislead. It is possible for the code to be both simple and wrong. I suppose the real lesson lies in testing. No matter how simple your code may be, there’s no substitute for testing it to make sure it’s actually doing what you think it is.